https://docs.spring.io/spring-batch/4.1.x/reference/html/spring-batch-intro.html#spring-batch-intro
https://qiita.com/kagamihoge/items/12fbbc2eac5b8a5ac1e0 俺の訳一覧リスト
1. Spring Batch Introduction
エンタープライズ領域の多くのアプリケーションはミッションクリティカル環境におけるビジネスオペレーションの実行にバルク処理を必要とします。これらのビジネスオペレーションには以下が含まれます。
- 大規模な情報の複雑な処理を、自動的に、ユーザ操作を介さず出来る限り効率的に処理します。これらのオペレーションは、基本的には、時間駆動のイベント(月末計算・通知・対応)を持ちます。
- 複数の大規模データセット(保険給付決定または料率調整)を繰り返し処理する複雑なビジネスルールを定期実行するアプリケーション。
- 内外システムから受信する情報の一貫性保持。これには、フォーマット・validation・そのシステムのレコードに投入するトランザクションルールでの処理、が必要となります。エンタープライズで日々数十億トランザクションを処理するのにバッチ処理を使います。
Spring Batchは軽量・包括的なバッチフレームワークで、エンタープライズシステムの日常的なオペレーションで不可欠であるロバストなバッチアプリケーション開発に用います。Spring BatchはSpring Frameworkの上にあるので開発者が期待する機能(効率的な、POJOベース開発など使い勝手の良い機能群)を備えており、開発者は必要に応じて高度なエンタープライズサービスの利用と活用が出来ます。Spring Batchはスケジューリングフレームワークではありません。エンタープライズのスケジューラは他に良いプロダクトが商用・OSSで多数存在します(Quartz, Tivoli, Control-Mなど)。設計意図としてはスケジューラと組み合わせて動作させ、スケジューラを置き換えるものではありません。
Spring Batchは、大量レコード処理・ログ/追跡・トランザクション管理・ジョブ処理統計・ジョブのリスタートとスキップ・リソース管理、で必要不可欠で繰り返し使用する機能を提供します。また、より高度でテクニカルなサービスも提供し、これらは最適化とパーティショニングを通じて極めて大量でハイパフォーマンスなバッチジョブを可能にします。Spring Batchは、複雑で大規模なユースケース(DB間で大規模データの移動や変換など)だけでなくシンプルなユースケース(ファイルを読んでDBに入れたり、ストアドを実行するなど)の、どちらでも使用出来ます。大規模バッチジョブで大量データを処理するにはフレームワークの非常にスケーラブルな機能が便利です。
1.1. Background
オープンソースソフトウェアプロジェクトとその関連コミュニティはwebとマイクロサービスのアーキテクチャフレームワークに強い関心を寄せていますが、エンタープライズIT環境ではバッチ処理のニーズが根強くあったにも関わらず、Javaベースのバッチ処理のニーズを満たすアーキテクチャフレームワークに対する関心が欠如していました。スタンダードとなるものが無く、バッチアーキテクチャは無数に増殖し、クライアントのエンタープライズIT環境でその企業専用に開発されていました。
SpringSource (now Pivotal) とAccentureはこれを変えるための協力をしました。Accentureのバッチアーキテクチャ実装における実事業と技術的経験、SpringSourceの深い技術的経験、Springの実績あるプログラミングモデルが、高品質でエンタープライズJavaでのギャップを埋めることを目的とした市場向けのソフトウェアを作成、これは自然で強力な協働関係を生みました。Springベースのバッチアーキテクチャソリューションを開発する際に似たような問題を解決してきた多数のクライアントと両社は開発をしてきました。これにより、実世界の課題に適用できるソリューションを保証する、実世界の制約と詳細をもたらしました。
AccentureはSpring Batchプロジェクトに以前からプロプライエタリなバッチ処理アーキテクチャフレームワークをコントリビュートし続けており、サポートのためのコミッタ―リソース・機能拡張・既存機能セット、の提供もしています。Accentureのコントリビュートは直近数世代のプラットフォーム、COBOL/Mainframe, C++/Unix, 最近ではJava/anywhere、でのバッチアーキテクチャ構築の数十年にわたる経験の裏付けがあります。
AccentureとSpringSourceの共同作業は、バッチアプリケーション作成時にエンタープライズのユーザが活用可能な、software processing approaches・フレームワーク・ツール、標準化の促進がねらいでした。スタンダードでエンタープライズIT環境に実証済みのソリューションを提供したい企業と政府機関はSpring Batchの恩恵を受けられます。
1.2. Usage Scenarios
一般的なバッチ処理は、
- DB・ファイル・キューから大量のレコードを読み込み。
- なんらかのデータ処理。
- 更新後の形式でデータを書き込み。
Spring Batchは、基本的にはユーザ操作を介さないオフライン環境で、上記のバッチのイテレーションを自動実行し、セットとしてトランザクション処理する機能を提供します。バッチのジョブはたいていのITプロジェクトの一部を形成しており、Spring Batchはロバストでエンタープライズスケールのソリューションを提供する唯一のオープンソースフレームワークです。
ビジネスシナリオとしては、
- 周期的にバッチ処理をコミット
- コンカレントなバッチ処理: ジョブのパラレル処理
- Staged, エンタープライズメッセージ駆動処理
- 大規模なパラレルバッチ処理
- 失敗後の手動もしくはスケジュールによるリスタート
- 依存ステップのシーケンシャル処理(ワークフロー駆動バッチのエクステンション使用)
- パーシャル処理: スキップ駆動(例: ロールバック時に使用)
- バッチ全体のトランザクション。バッチサイズが小さいか既存のストアドプロシージャないしスクリプトを実行する場合など。
技術上の目的としては、
- バッチ処理の開発者はSpringのプログラミングモデルを使用する: ビジネスロジックに集中し、インフラ部分はフレームワークに任せる。
- インフラ・バッチ実行環境・バッチアプリケーションそれぞれの関心事を明確に分離する。
- インターフェースの形で汎用的なコア実行サービスを提供し、プロジェクトでそれを実装する。
- 基本的にはそのまま使用できる、コア実行インタフェースのシンプルなデフォルト実装を提供する。
- springフレームワークをすべてのレイヤで活用し、設定・カスタマイズ・サービス拡張を容易にする。
- シンプルなデプロイメントモデルを提供し、バッチのjarはMavenでビルドするアプリケーションと完全に分離する。
1.3. Spring Batch Architecture
Spring Batchは拡張性と多様なユーザをターゲットに設計しています。以下は拡張性と開発容易性のためのレイヤーアーキテクチャを示した図です。
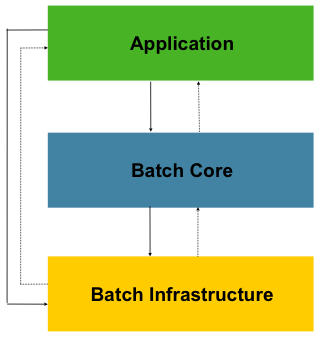
Figure 1. Spring Batch Layered Architecture
このレイヤーアーキテクチャは三つの主要な高レベルコンポーネント、Application, Core, Infrastructure、に焦点を当てています。ApplicationはSpring Batchを使用する開発者が書くコードとすべてのバッチジョブです。Batch Coreはバッチジョブの起動と制御に必要なコアランタイムクラスで、JobLauncher, Job, Stepの実装があります。ApplicationとCoreは両者とも共通インフラ上に作ります。このインフラには汎用のリーダー・ライター・サービス(RetryTemplateなど)があり、これらはアプリケーション開発者(リーダーItemReaderとライターItemWriterなど)とコアフレームワーク自身(リトライは自前のライブラリ)の両方が使用します。
1.4. General Batch Principles and Guidelines
以下の核となる原則、ガイドライン、一般的な考慮事項はバッチソリューションの構築時に一考すべきです。
- バッチのアーキテクチャは基本的にはオンラインのそれに影響を与えるし、逆もまた真です。可能な限り共通のコンポーネントでアーキテクチャと環境を設計するよう心掛けてください。
- 可能な限りシンプルにして、単一バッチアプリケーションに複雑なロジック構造を作り込むのは避けて下さい。
- 処理とデータストレージは物理的に近くに置いて下さい(つまり処理が発生場所にデータを置く)
- 特にI/Oのシステムリソース使用を最小化する。可能な限りオペレーションを内部メモリで実行する。
- 不要な物理I/Oの回避を確認するためアプリケーションI/O(SQLの分析)をレビューする。特に、以下4つのありがちなミスを見つける必要があります。 あるデータを一度読んでワーキング領域に保持したりキャッシュ出来るのに、トランザクションのたびにデータを読み込む。 あるデータを同一トランザクションの最初の方で読んでいるのに、再度データを読み込む。 不要なテーブルもしくはインデックススキャンを発生させる。 SQLのWHEREにキーを指定しない。
- バッチ実行中に二回同じことをしない。たとえば、レポーティングで何らかのデータ集約をする場合、初回データ処理の際に集約データを(できれば)保存し、レポーティングアプリケーションで同一データの再処理を避けて下さい。
- ある処理中に時間のかかるアロケーションの再発生を避けるには、バッチアプリケーションの開始時に十分なメモリを割り当ててください。
- データ整合性は常に最悪を想定してください。十分なチェックとデータ整合性を維持するレコードvalidationを実装してください。
- 必要に応じて内部的なvalidationにチェックサムを実装してください。たとえば、フラットファイルがファイルの総レコード数およびキーフィールドの集約があるtrailer recordを持つ場合など。
- 負荷テストの計画と実施を実データと本番環境でなるべく早期に行ってください。
- 大規模バッチシステムでは、バックアップが困難な場合があり、特に24-7が基本のオンラインでコンカレントに実行する場合です。DBバックアップは基本的にはオンラインのバックアップ機能がありますが、ファイルバックアップも同様に重要な考慮が必要です。バッチがフラットファイルに依存する場合、ファイルバックアップ処理はしかるべき設定とドキュメント化だけでなく、定期的に十分なテストをしてください。
1.5. Batch Processing Strategies
バッチシステムの設計と実装の指針となるよう、基本的なバッチアプリケーションの構成要素とパターンを、設計者と開発者にサンプルの構造図とcode shellsで示します。バッチジョブの設計をする時、ビジネスロジックは以下の標準的な構成要素で実装出来るよう複数のステップに分解します。
- Conversion Applications: ファイルが外部システムへ生成もしくは提供される種類の場合、提供されるトランザクションレコードを処理に必要な形式へと変換するアプリケーションを構築します。この種のバッチアプリケーションは一部または全体的に変換ユーティリティモジュールで構築します(Basic Batch Services参照)。
- Validation Applications: validationアプリケーションはすべての入出力レコードが正確かつ矛盾の無いことを保証します。validationは基本的には、ヘッダーとフッター、チェックサムとvalidationアルゴリズム、レコード単位のクロスチェック、で作成します。
- Extract Applications: この種のアプリケーションは、データベースや入力ファイルからレコードセットを読み込み、定義済みルールでレコードを選択し、出力ファイルにレコードを書き込みます。
- Extract/Update Applications: アプリケーションがDBないし入力ファイルからレコードを読み込み、DB更新あるいは入力レコード各行に応じて出力ファイルを作成する。
- Processing and Updating Applications: 抽出やvalidationアプリケーションからの入力トランザクションに対する処理を実行するアプリケーション。通常、この処理は必要なデータ取得のためのDB読み込みがあり、出力処理としてDB更新やレコード作成を伴う場合もある。
- Output/Format Applications: アプリケーションで入力ファイルを読み込み、そのレコードのデータを何らかの標準フォーマットで再構成し、別のプログラムやシステムで表示や変換するための出力ファイルを生成する。
なお、前述の構築部品では作れないビジネスロジック用の、基礎的なアプリケーションシェルも必要です。
主要な構築部品に加え、個々のアプリケーションは一つ以上の標準ユーティリティステップを使用する場合があります。例えば、
- Sort: 入力ファイルを読み込んでソートキーで並べ替えした出力ファイルを生成するプログラム。ソートは通常は標準システムユーティリティを使用する。
- Split: 単一入力ファイルを読み込んで入力行に応じていずれかの出力ファイルに書き込むプログラム。スプリットはパラメータ駆動の標準システムユーティリティで実装あるいは設定します。
- Merge: 複数入力ファイルから読み込んだレコードを統合して単一の出力ファイルを生成するプログラム。スプリットはパラメータ駆動の標準システムユーティリティで実装あるいは設定します。
また、バッチアプリケーションは入力ソースによる分類もあります。
- DB駆動アプリケーションはDBから取得した行や値を基に動作する。
- ファイル駆動アプリケーションはファイルから取得した行や値を基に動作する。
- メッセージ駆動アプリケーションはメッセージキューから取得したメッセージを基に動作する。
バッチシステムの中核は処理方針です。方針の選択に影響を与える要因としては、概算バッチシステムボリューム、オンラインシステムや他のバッチシステムとの同時並行性、利用可能なバッチウィンドウ*1、があります。(ただし、より多くのエンタープライズ環境が24-7稼働を望んでいるので、明確なバッチウィンドウが消失している)
バッチの一般的な処理オプション(実装の複雑性を増加させる)は以下のとおりです。
- オフラインモードのバッチウィンドウ内では通常処理。
- コンカレントバッチ or オンライン処理を選べる。
- 多数の異なるバッチをパラレル処理、あるいは、同時にジョブをパラレル処理。
- パーティショニング(同時に同一ジョブの複数インスタンスを処理)
- 先行オプションの組み合わせ(A combination of the preceding options)
これらオプションのいくつかあるいは全部を商用スケジューラでサポートしている場合があります。
以降のセクションではこれら処理オプションの詳細について解説します。この点は重要で、経験則として、バッチ処理が採るコミットとロッキングストラテジは処理の種類に依存するので、そのオンラインのロッキングストラテジも同一方針を利用します。そうすると、全体アーキテクチャの設計時にバッチアーキテクチャを単なる後付けには出来ません。
ロッキングストラテジは単にDBのロックを使う場合もあれば、そのアーキテクチャでカスタムのロッキングサービスを実装する場合もあります。ロッキングサービスはDBロックに追従(例えば、専用のDBテーブルに必要情報を保存するなど)し、DB操作を要求するアプリケーションプログラムにパーミッションを与えたり拒否したりします。リトライロジックもこのアーキテクチャで実装可能で、ロックが絡む場合にバッチジョブのアボートを回避します。
1. Normal processing in a batch window データ更新があり別々のバッチウィンドウで動作するシンプルなバッチ処理で、オンラインユーザや他のバッチ処理が居ない場合、同時並行性は問題とはならずバッチ実行の最後で単一コミットを実行できます。
大半のケースで、最もロバストな方針が最も適切です。バッチシステムは時が経つにつれて、複雑性と扱うデータボリューム両方が、拡大する傾向に注意してください。ロッキングストラテジを正しく実装しない場合、そのシステムは単一のコミットポイントに依存する事となり、バッチプログラムの修正が困難となります。よって、極めて単純なバッチシステムであっても、リスタート&リカバリのコミットロジックの必要性と、以降のセクションで解説する複雑なケースについても考慮してくださ。
2. Concurrent batch or on-line processing オンラインのユーザからも同時に更新されうるデータをバッチアプリケーションで処理する場合、オンラインで数秒以上必要となるデータ(DBやファイル)はロックしない方が良いです。また、更新は少数のトランザクションが終わるごとにコミットします。それにより、他プロセスで利用できないデータとその時間を最小化します。
物理ロックを最小化する他のオプションとしては、楽観的ロックか悲観的ロックどちらかのパターンで低レベルの論理ロックを実装します。
- 楽観ロックはレコード競合の可能性が低い前提条件を想定します。これは通常、DBテーブルにタイムスタンプのカラムを定義し、バッチとオンライン処理双方で同時に使用します。アプリケーションが処理で行を取得するとき、タイムスタンプも取得します。次に、アプリケーションが処理対象行を更新するとき、WHERE節にオリジナルのタイムスタンプを使用してUPDATEします。タイムスタンプが合致する場合、データとタイムスタンプは更新されます。もしタイムスタンプが不一致の場合、別のアプリケーションが取得と更新の間に同一行を更新していることを意味します。よって、その更新は実行できません。
- 悲観ロックはレコード競合の可能性が高い前提条件を想定するため、取得時に物理か論理ロックを必要とします。ある種の悲観的な論理ロックはDBテーブルにロック用のカラムを使用します。アプリケーションが更新で行を取得するとき、ロック用カラムにフラグをセットします。そのフラグを見て、同一行を取得しようとする他アプリケーションは論理レベルで失敗します。フラグをセットするアプリケーションが行を更新するとき、フラグも一緒にクリアすることで、他のアプリケーションからその行が取得可能になります。なお、データの整合性を初回取得とフラグセットの間も維持する事が必須です(例えばDBロック(
SELECT FOR UPDATE)などを使用)。また、このやり方は物理ロックと同様の欠点を持ちますが、レコードロック中にユーザが昼飯に行った場合にロックをタイムアウトさせるメカニズムを構築するのが多少簡単なのが異なります。
これらのパターンは必ずしもバッチ処理に最適ではないですが、コンカレントバッチとオンライン処理ではたいてい使用します(DBが行レベルロックをサポートしない場合など)。一般的には、楽観ロックはオンラインアプリケーションに適し、悲観ロックはバッチアプリケーションに適します。論理ロックを使用する場合は、論理ロックで保護するデータエンティティにアクセスするすべてのアプリケーションで同一の方式を採用することが必須となります。
これらの方法は単一レコードのロックを扱うに過ぎない点に注意してください。場合によって、論理的に関連のあるレコードグループのロックの必要が出てきます。物理ロックでは、デッドロックの可能性を避けるために極めて注意深くレコードグループを管理してください。論理ロックでは、保護したい論理レコードグループを管理可能な論理ロックマネージャを構築するのがベストで、このマネージャが一貫性と非デッドロックを保証します。通常、論理ロックマネージャは、ロック管理・競合レポート・タイムアウト機構・他色々、を行うためのテーブルを持ちます。
3. Parallel Processing パラレル処理は、合計処理時時間最小化のため、複数バッチ実行あるいはパラレルにジョブ実行を行います。これはジョブが、同一ファイル・DBテーブル・インデックス空間、を共有しないのであれば問題はありません。共有する場合、サービスはパーティションデータによる実装の必要が出てきます。別の方法として、制御テーブル(control table)で相互依存関係を維持させるアーキテクチャモジュールを構築します。制御テーブルは共有リソースそれぞれに対する行を持ち、その行がアプリケーションで使用中かどうかを持ちます。パラレルジョブのバッチアーキテクチャやアプリケーションは必要とするリソースへのアクセスを取得可能かどうかを確認するために制御テーブルから情報を取得します。
データアクセスが問題とならない場合、パラレル処理にスレッドを追加しての実装が可能です。メインフレーム環境では、すべてのプロセスで十分なCPUタイムを保証する目的で、パラレルジョブクラスが伝統的に使用されています。つまるところ、すべての実行プロセスでタイムスライスを保証するのに十分ロバストでなければなりません。
パラレル処理の別の課題には、ロードバランシング、一般的なシステムリソース、例えばファイル・DBバッファプールなどの可用性、があります。また、制御テーブル自体がたやすくクリティカルなリソースになる危険性があります。
4. Partitioning パーティショニングにより大規模なバッチアプリケーションの複数バージョンをコンカレントに実行できます。この用途は長時間バッチジョブの処理時間短縮です。正常にパーティション化可能なプロセスとは、スプリット可能な入力ファイルや異なるデータセットに対して実行可能なパーティションテーブル、を使用します。
また、パーティション化プロセスは割り当てられたデータセットのみを処理するよう設計する事が必須です。パーティショニングアーキテクチャはDB設計とDBのパーティショニング方法と密接な関係を持ちます。なお、DBパーティショニングは必ずしもDBの物理パーティショニングを意味するわけではありませんが、基本的にはそれを推奨します。下図はパーティショニングのアプローチです。
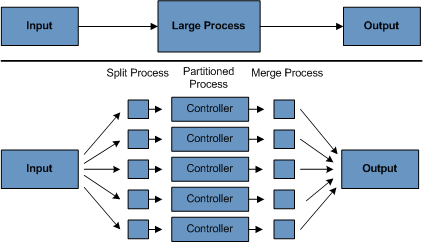
このアーキテクチャはパーティション数を動的設定可能にするため十分に柔軟にします。自動と手動設定の両方が考えられます。自動設定は入力ファイルサイズと入力レコード数などのパラメータに基づく事になると思われます。
4.1 Partitioning Approaches パーティショニング方針の選択はケースバイケースです。以下はいくつかのパーティショニング方針の解説です。
1. Fixed and Even Break-Up of Record Set
この方針では入力レコードセットを(例えば10であれば、各グループはレコードセット全体の1/10となります)偶数のグループに分割します。各グループは単一のバッチ/抽出アプリケーションで処理します。
この方針を使用する際には、事前処理としてレコードセットの分割が必要です。分割結果は上限下限となり、その番号はバッチ/抽出アプリケーションへの入力に用い、そのグループのみ処理するために使われます。
事前処理のオーバーヘッドが大きくなりすぎる可能性があり、これはレコードセットのグループ境界の計算と決定が必要なためです。
2. Break up by a Key Column
この方針では入力レコードを、キーカラム・ロケーションコード・各キーからバッチインスタンスに割り当てたデータ、で分割します。これを行うには、カラム値を以下いずれかにします。
前者の場合、新しい値の追加はバッチ/抽出の手動再設定を意味します。これは新しい値が特定インスタンスに追加されることを保証するためです。
後者の場合、すべての値がバッチジョブインスタンスを介してカバーされることが保証されます。ただし、一つのインスタンスで処理する件数はカラム値の分布に依存します(0000-0999は多数で、1000-1999は少数しかない場合があり得る)。この方針の場合、データ範囲はパーティショニング前提で設計する必要があります。
両者とも、バッチインスタンスに渡すレコードの最適均等配分は出来ません。バッチインスタンスの個数設定が動的では無いためです。
3. Breakup by Views
この方針は基本的にはDBレベルではないキー列で分割します。レコードセットをビューに分割します。このビューを処理中にバッチアプリケーションの個々のインスタンスで使用します。分割はデータのグルーピングにより行います。
この方針では、バッチアプリケーションの個々のインスタンスは(元のテーブルではなく)特定のビューに紐付けます。新規データ追加時、データの新規グループをビューに含めます。動的設定の機能は無く、インスタンス数の変更をするとビューも変更になります。 4. Addition of a Processing Indicator
この方針はインジケーター役となる新規列を入力テーブルに追加します。事前処理段階では、すべてのインジケーターは未処理になっています。バッチアプリケーションのフェッチ段階で、未処理状態のレコードが読み込まれ、一度読み込まれると(ロック扱い)、処理中状態になります。そのれおーどが処理完了すると、インジケーターは完了かエラーのどちらかで更新します。大量のバッチアプリケーションを変更無しに開始可能で、これはインジケーター列でレコードが一度だけ処理したことを保証するためです。端的に言えば"完了時、インジケータが完了状態になる"です。
この方針では、テーブルへのI/Oは動的に増加します。更新系の場合、いずれにせよ書き込みが不可避なので、影響は少ないです。
5. Extract Table to a Flat File
この方針はテーブルをファイルに抽出します。このファイルは複数セグメントに分割し、バッチインスタンスの入力になります。
この方針では、テーブルからファイル抽出と分割の追加オーバーヘッドが発生し、マルチパーティショニングの効果を打ち消す可能性があります。ファイル分割スクリプトの変更により動的設定が可能です。
6. Use of a Hashing Column
レコードを決定するのに使用するハッシュカラム(key/index)をDBテーブルに付けます。このハッシュカラムにはインジケーターを持ち、バッチアプリケーションのインスタンスがどの行を処理するかを決定するのに使用します。たとえば、3つのバッチインスタンスがあるとして、1番インスタンスが処理する行のインジケーターには'A'、2番インスタンスは'B'、3番インスタンスは'C'、にします。
レコードを参照する時には、特定のインジケーターを持つすべての行を選択するためにWHEREを追加します。テーブルへのINSERT時には、デフォルトのインスタンスを示す値(例.'A')をインジケーターカラムに設定します。
インジケータの更新にはシンプルなバッチアプリケーションを使用し、たとえば、異なるインスタンス間で負荷の再配分をします。極めて大量の新規行を追加する時に、新規行を別のインスタンスに振り分け直すのにこのバッチを使います(バッチウィンドウを除けば何時でもOK)。
新規インスタンス用にインジケーターを再配分するには前述の通りなので、追加インスタンスは単にバッチを実行するだけです。
4.2 Database and Application Design Principles
キー列でのパーティションテーブルを使用するアプリケーション方針のアーキテクチャは、パーティションパラメータを格納するセントラルパーティションリポジトリを持ちます。このリポジトリは単一テーブルを持ち、いわゆるpartition tableと呼ばれています。
partition tableに持つ情報は、基本的には静的で、DBAがメンテナンスします。このテーブルはアプリケーションの個々のパーティションに対する一行を持ちます。カラムには、Program ID Code, Partition Number(パーティションの論理ID), パーティションで使うDBキーカラムのLow ValueとHigh Value、を持ちます。
プログラム開始時に、program idとpartition numberをアーキテクチャからアプリケーションに渡します(具体的には、Control Processing Taskletから渡す)。キー列を使用する方針の場合、アプリケーションで処理するデータ範囲を決定するpartition tableを読むのにこれらの変数を使用します。また、partition numberは以下の処理でも使用します。
- 適切なマージ処理を実行するため、出力ファイルやDB更新に追加
- バッチログへの正常処理レポートやアーキテクチャエラーハンドラに何らかのエラーを報告
4.3 Minimizing Deadlocks
アプリケーションをパラレルやパーティションで動作させる場合、DBリソースの競合とデッドロックの可能性があります。重要なのは、DB設計チームが潜在的な競合の可能性を削除することで、これをなるべくDB設計の一部として実施します。
また、開発者はデッドロック防止とパフォーマンスに気を付けつつDBのインデックステーブルを設計すべきです。
デッドロックやホットスポットが、ログテーブル・制御テーブル・ロックテーブルなど、管理やアーキテクチャが持つテーブルで発生することがあります。これらの影響も同様に気を付ける必要があります。本番に近い負荷テストでアーキテクチャに発生しうるボトルネックを特定することが重要です。
データのコンフリクトの影響を最小化するため、DB接続時やデッドロック発生時に、アーキテクチャはwait-and-retryなどのサービスを提供すべきです。これはDBの特定のリターンコードに対応する機構で、エラーを即時報告するのではなく、所定時間待機してDB操作をリトライします。
4.4 Parameter Passing and Validation
パーティションアーキテクチャはアプリケーション開発者になるべく透過的であるべきです。パーティションモードのアプリケーション実行に紐付くすべてのタスクをアーキテクチャが実行します。
validationは以下をチェックします。
データベースがパーティション化されている場合、その単一パーティションがDBパーティションを拡張していないことを確認するvalidationも必要な場合があります。
また、アーキテクチャはパーティションの統合を考慮に入れておきます。
*1:ディスクバックアップとか時間制約が強いバッチで利用可能な時間のこと