https://docs.spring.io/spring-batch/4.1.x/reference/html/readersAndWriters.html#readersAndWriters
https://qiita.com/kagamihoge/items/12fbbc2eac5b8a5ac1e0 俺の訳一覧リスト
1.7. XML Item Readers and Writers
Spring BatchはXMLを読み込みJavaオブジェクトへのマッピングとその逆の書き込みを行うtransactionalな機能を提供します。
※ Constraints on streaming XML I/OにはStAX APIを使用しますが、これは他の標準XMLパースAPIはバッチ処理には向かないためです(DOMはメモリに入力全体をロードするし、SAXはパース処理の制御をコールバックでしか出来ません)
Spring BatchにおけるXML入出力の扱いを知る必要があります。まず、読み込みと書き込みはいくつか異なる概念がありますが、Spring Batch XMLとしては共通です。XML処理では、トークン処理するレコード行(FieldSet)ではなく、レコードに対応する'fragments'のコレクションとしてXMLリソースを捉えます。以下がそのイメージです。
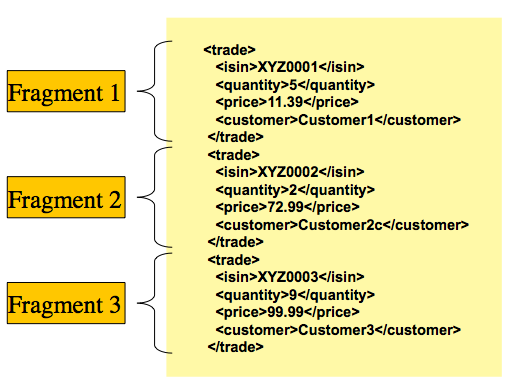
Figure 1. XML Input
ここでは'trade'タグを'root element'として定義しています。'fragment'はすべて'
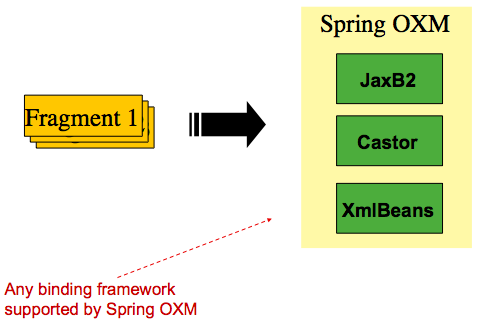
Figure 2. OXM Binding
OXMの概要とレコード表現にXML framentsを使うことを簡単に解説し、基礎を確認したところでreaderとwriterの詳細を解説します。
1.7.1. StaxEventItemReader
StaxEventItemReaderの設定ではXML入力ストリームからレコードを処理するための基本的なセットアップを行います。まず、以下のStaxEventItemReaderで処理可能なXMLレコードセットを考えます。
<?xml version="1.0" encoding="UTF-8"?> <records> <trade xmlns="http://springframework.org/batch/sample/io/oxm/domain"> <isin>XYZ0001</isin> <quantity>5</quantity> <price>11.39</price> <customer>Customer1</customer> </trade> <trade xmlns="http://springframework.org/batch/sample/io/oxm/domain"> <isin>XYZ0002</isin> <quantity>2</quantity> <price>72.99</price> <customer>Customer2c</customer> </trade> <trade xmlns="http://springframework.org/batch/sample/io/oxm/domain"> <isin>XYZ0003</isin> <quantity>9</quantity> <price>99.99</price> <customer>Customer3</customer> </trade> </records>
XMLレコードの処理には以下が必要です。
- Root Element Name: マッピング対象オブジェクトとなるfragmentのroot要素の名前。上記設定ではtradeがそれに当たります。
- Resource: 読み込むファイルのSpringのResource
Unmarshaller: XML fragmentからオブジェクトにマッピングするためのSpring OXMが提供するアンマーシャル機能。
以下の例は、tradeというroot要素、org/springframework/batch/item/xml/domain/trades.xmlというリソース、tradeMarshallerというアンマーシャル、を定義しています。
Java Configuration
@Bean public StaxEventItemReader itemReader() { return new StaxEventItemReaderBuilder<Trade>() .name("itemReader") .resource(new FileSystemResource("org/springframework/batch/item/xml/domain/trades.xml")) .addFragmentRootElements("trade") .unmarshaller(tradeMarshaller()) .build(); }
上の例では、XStreamMarshallerを使用しています。このクラスは最初のkeyがfragment(root要素)名でvalueがバインド型のmapを渡せます。FieldSet同様、フィールドにマッピングするroot以外の要素はmapのkey/valueで指定します。設定では、このエイリアスを設定するためのSpring configuration utilityを使います。
Java Configuration
@Bean public XStreamMarshaller tradeMarshaller() { Map<String, Class> aliases = new HashMap<>(); aliases.put("trade", Trade.class); aliases.put("price", BigDecimal.class); aliases.put("isin", String.class); aliases.put("customer", String.class); aliases.put("quantity", Long.class); XStreamMarshaller marshaller = new XStreamMarshaller(); marshaller.setAliases(aliases); return marshaller; }
入力では、readerは次のfragmentが現れたと解釈するまでXMLリソースを読みます。デフォルトでは、raaderが次のfragmentが現れたと解釈するのは要素名とのマッチングで行います。readerはfragmentからスタンドアローンのXMLドキュメントを生成し、XMLをJavaオブジェクトにマッピングするデシリアライザー(基本的にはSpring OXM Unmarshallerのラッパー)に渡します。
まとめると、Spring configurationのインジェクションを使用して上記の流れをJavaコードで書くと以下のようになります。
StaxEventItemReader<Trade> xmlStaxEventItemReader = new StaxEventItemReader<>(); Resource resource = new ByteArrayResource(xmlResource.getBytes()); Map aliases = new HashMap(); aliases.put("trade","org.springframework.batch.sample.domain.trade.Trade"); aliases.put("price","java.math.BigDecimal"); aliases.put("customer","java.lang.String"); aliases.put("isin","java.lang.String"); aliases.put("quantity","java.lang.Long"); XStreamMarshaller unmarshaller = new XStreamMarshaller(); unmarshaller.setAliases(aliases); xmlStaxEventItemReader.setUnmarshaller(unmarshaller); xmlStaxEventItemReader.setResource(resource); xmlStaxEventItemReader.setFragmentRootElementName("trade"); xmlStaxEventItemReader.open(new ExecutionContext()); boolean hasNext = true; Trade trade = null; while (hasNext) { trade = xmlStaxEventItemReader.read(); if (trade == null) { hasNext = false; } else { System.out.println(trade); } }
1.7.2. StaxEventItemWriter
StaxEventItemWriterはResource, マーシャラー, rootTagNameが必要です。マーシャラーに渡すJavaオブジェクト(通常はSpring OXM Marshaller)はカスタムイベントライターでResourceに書き込みます。カスタムイベントライターはOXMツールが個々のfragmentでパブリッシュですStartDocumentとEndDocumentのイベントをフィルタします。以下はStaxEventItemWriterを使う例です。
Java Configuration
@Bean public StaxEventItemWriter itemWriter(Resource outputResource) { return new StaxEventItemWriterBuilder<Trade>() .name("tradesWriter") .marshaller(tradeMarshaller()) .resource(outputResource) .rootTagName("trade") .overwriteOutput(true) .build(); }
上の設定例は3つの必須プロパティとoverwriteOutput=true属性を設定しており、この属性は本チャプター前半で説明したように、既存ファイルを上書き可能かどうかを指定します。以下のサンプルのwriterで使用しているマーシャラーは上述のreadringのサンプルで使用したものと完全に同じな点に注意してください。
Java Configuration
@Bean public XStreamMarshaller customerCreditMarshaller() { XStreamMarshaller marshaller = new XStreamMarshaller(); Map<String, Class> aliases = new HashMap<>(); aliases.put("trade", Trade.class); aliases.put("price", BigDecimal.class); aliases.put("isin", String.class); aliases.put("customer", String.class); aliases.put("quantity", Long.class); marshaller.setAliases(aliases); return marshaller; }
以上を要約すると、以下のようなJavaコードになります。
FileSystemResource resource = new FileSystemResource("data/outputFile.xml") Map aliases = new HashMap(); aliases.put("trade","org.springframework.batch.sample.domain.trade.Trade"); aliases.put("price","java.math.BigDecimal"); aliases.put("customer","java.lang.String"); aliases.put("isin","java.lang.String"); aliases.put("quantity","java.lang.Long"); Marshaller marshaller = new XStreamMarshaller(); marshaller.setAliases(aliases); StaxEventItemWriter staxItemWriter = new StaxEventItemWriterBuilder<Trade>() .name("tradesWriter") .marshaller(marshaller) .resource(resource) .rootTagName("trade") .overwriteOutput(true) .build(); staxItemWriter.afterPropertiesSet(); ExecutionContext executionContext = new ExecutionContext(); staxItemWriter.open(executionContext); Trade trade = new Trade(); trade.setPrice(11.39); trade.setIsin("XYZ0001"); trade.setQuantity(5L); trade.setCustomer("Customer1"); staxItemWriter.write(trade);
1.8. JSON Item Readers And Writers
Spring Batchは以下フォーマットのJSONリソースの読み書き機能を提供します。
[ { "isin": "123", "quantity": 1, "price": 1.2, "customer": "foo" }, { "isin": "456", "quantity": 2, "price": 1.4, "customer": "bar" } ]
JSONリソースとは、個々のアイテムに対応するJSONオブジェクトの配列、という想定です。Spring Batchは特定のJSONライブラリには依存しません。
1.8.1. JsonItemReader
JsonItemReaderはJSONのパースとバインディングをorg.springframework.batch.item.json.JsonObjectReaderインタフェースの実装にデリゲートします。chunkでJSONオブジェクトを読み込むためにストリーミングAPIを使用して実装するように設計されています。現在は2つの実装が含まれます。
- Jackson
org.springframework.batch.item.json.JacksonJsonObjectReader - Gson
org.springframework.batch.item.json.GsonJsonObjectReader
JSONレコードを処理するには以下が必要です。
Resource: 読み込むJSONファイルのSpring Resource.JsonObjectReader: JSONオブジェクトリーダーでパースしてアイテムをJSONオブジェクトにバインドする。
以下の例は、前述のJSONリソースorg/springframework/batch/item/json/trades.jsonをJacksonベースのJsonObjectReaderで処理するJsonItemReaderの定義例です。
@Bean public JsonItemReader<Trade> jsonItemReader() { return new JsonItemReaderBuilder<Trade>() .jsonObjectReader(new JacksonJsonObjectReader<>(Trade.class)) .resource(new ClassPathResource("trades.json")) .name("tradeJsonItemReader") .build(); }
1.8.2. JsonFileItemWriter
JsonFileItemWriterはアイテムのマーシャリングをorg.springframework.batch.item.json.JsonObjectMarshallerにデリゲートします。このインタフェースの仕様はオブジェクトを取りJSON Stringにマーシャリングします。現在2つの実装があります。
- Jackson
org.springframework.batch.item.json.JacksonJsonObjectMarshaller - Gson
org.springframework.batch.item.json.GsonJsonObjectMarshaller
JSONレコードを書き込むには以下が必要です。
以下はJsonFileItemWriterの定義例です。
@Bean public JsonFileItemWriter<Trade> jsonFileItemWriter() { return new JsonFileItemWriterBuilder<Trade>() .jsonObjectMarshaller(new JacksonJsonObjectMarshaller<>()) .resource(new ClassPathResource("trades.json")) .name("tradeJsonFileItemWriter") .build(); }
1.9. Multi-File Input
単一Stepで複数ファイルを処理したい場合があります。ファイルがすべて同一フォーマットの場合、MultiResourceItemReaderがXMLとフラットフファイル処理用のその種の入力をサポートします。ディレクトリに以下ファイルがあるとします。
file-1.txt file-2.txt ignored.txt
file-1.txtとfile-2.txtは同一フォーマットで、業務上の仕様により、一緒に処理する必要があります。MultiResourceItemReaderでは以下例のようにワイルカードで両ファイルを読み込めます。
Java Configuration
@Bean public MultiResourceItemReader multiResourceReader() { return new MultiResourceItemReaderBuilder<Foo>() .delegate(flatFileItemReader()) .resources(resources()) .build(); }
デリゲート先は単にFlatFileItemReaderです。上の設定は両ファイルから入力を読み込み、ロールバックとリスタートを処理します。注意点として、ItemReader同様、リスタート時に入力(この場合はファイル)を増やすと何らかの問題を起こす原因となる場合があります。バッチジョブは正常終了するまで固有のディレクトリを持つことを推奨します。
※ 入力リソースの順序はMultiResourceItemReader#setComparator(Comparator)で決められ、is preserved between job runs in restart scenario.
1.10. Database
通常のエンタープライズアプリケーションでは、データベースはバッチにおいて中心となるストレージ機構です。しかし、バッチはそのシステムを動作させるデータセットのサイズが大きくという点で他のアプリケーションとは異なります。SQLが100万行返す場合、全行読み終えるまで結果セットをメモリに保持するでしょう。Spring Batchはこの課題に対して2種類のソリューションを提供します。
- Cursor-based ItemReader Implementations
- Paging ItemReader Implementations
1.10.1. Cursor-based ItemReader Implementations
データベースカーソルはバッチ開発者の基本的なアプローチで、これは'ストリームな'リレーショナルデータという問題に対するデータベースの解決策です。Java ResultSetクラスは基本的にはカーソル操作を行うオブジェクト指向の機能です。ResultSetはデータの現在行のカーソルを保持します。ResultSetのnextを呼ぶとカーソルは次の行に移ります。Spring BatchのカーソルベースのItemReader実装は、初期化時にカーソルをオープンしてread呼び出しの度に1行カーソルを進めて、処理用にマッピングオブジェクトを返します。closeはすべてのリソースの解放を保証するために呼びます。Spring coreのJdbcTemplateはこの問題を回避するのにResultSetの全行をすべてマッピングするコールバックを使用し、呼び出し側に制御を戻す前にcloseします。ただ、バッチでは、stepが完了するまでwaitすることになります。以下の図はカーソルベースItemReaderの動作概要です。注意点として、この例はSQL(最も一般的なので)を使用していますが、任意のテクノロジでこのベーシックなアプローチを採れます。
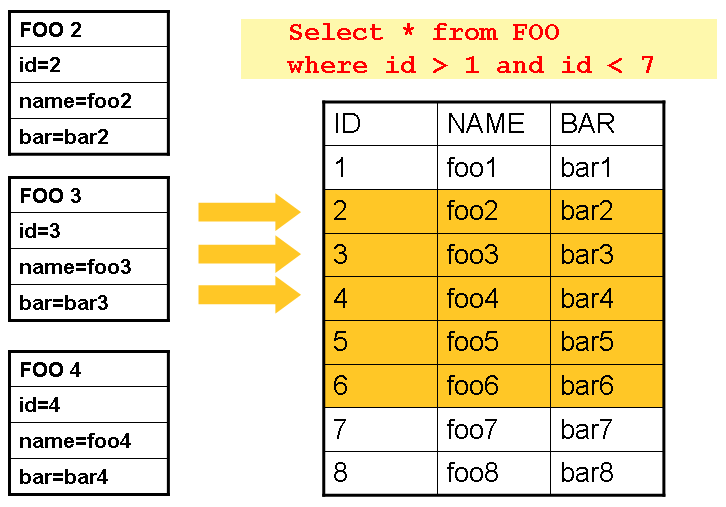
Figure 3. Cursor Example
これは基本的なパターンを図示しています。'FOO'テーブルは3つのカラム、ID, NAME, BARがあり、IDが1より大きく7より小さい行をselectしています。カーソルはID 2(1行目)から開始します。この結果行はFooオブジェクトにマッピングします。再度read()を呼ぶとカーソルは次の行に移動し、FooのIDは3になります。読み込み結果はread後に書き込まれ、その後オブジェクトはGC可能となります(このオブジェクトへの参照が無いと仮定)。
JdbcCursorItemReader
JdbcCursorItemReaderはカーソルベースのJDBC実装です。ResultSetを直接処理し、DataSourceから得たコネクションに対してSQLを実行します。サンプルでは以下のデータベーススキーマを使います。
CREATE TABLE CUSTOMER ( ID BIGINT IDENTITY PRIMARY KEY, NAME VARCHAR(45), CREDIT FLOAT );
通常は各行に対するドメインオブジェクトを使うので、以下の例はRowMapper実装によりCustomerCreditにマッピングしています。
public class CustomerCreditRowMapper implements RowMapper<CustomerCredit> { public static final String ID_COLUMN = "id"; public static final String NAME_COLUMN = "name"; public static final String CREDIT_COLUMN = "credit"; public CustomerCredit mapRow(ResultSet rs, int rowNum) throws SQLException { CustomerCredit customerCredit = new CustomerCredit(); customerCredit.setId(rs.getInt(ID_COLUMN)); customerCredit.setName(rs.getString(NAME_COLUMN)); customerCredit.setCredit(rs.getBigDecimal(CREDIT_COLUMN)); return customerCredit; } }
JdbcCursorItemReaderはJdbcTemplateと同じインタフェースを使うため、ItemReaderとの比較のため、JdbcTemplateでのデータ読み込み方法を見ておくと参考になります。例として、CUSTOMERデータベースに1,000行あるとします。最初はJdbcTemplateを使う例です。
//説明簡略化のため、dataSourceは準備済みとする。 JdbcTemplate jdbcTemplate = new JdbcTemplate(dataSource); List customerCredits = jdbcTemplate.query("SELECT ID, NAME, CREDIT from CUSTOMER", new CustomerCreditRowMapper());
上のコードを実行すると、customerCredits listには1,000CustomerCreditオブジェクトが入ります。queryメソッドの内部では、DataSourceからコネクションを取得し、SQLを実行し、ResultSetの各行に対しmapRowメソッドを呼びます。JdbcCursorItemReaderと比較すると、以下のようなコードになります。
JdbcCursorItemReader itemReader = new JdbcCursorItemReader(); itemReader.setDataSource(dataSource); itemReader.setSql("SELECT ID, NAME, CREDIT from CUSTOMER"); itemReader.setRowMapper(new CustomerCreditRowMapper()); int counter = 0; ExecutionContext executionContext = new ExecutionContext(); itemReader.open(executionContext); Object customerCredit = new Object(); while(customerCredit != null){ customerCredit = itemReader.read(); counter++; } itemReader.close();
上のコードを実行すると、counterは1,000になります。上のコードでcustomerCreditをリストに入れる場合、最終的な結果はJdbcTemplateの場合と同じになります。ただし、ItemReaderの大きな利点はアイテムのストリーム処理が可能な点にあります。readメソッドを1度だけ呼んだ後にそのアイテムをItemWriterで書き込み、それから、次のアイテムをreadで取得します。これによりアイテム読み込みと書き込みの'chunk'処理と定期コミットが可能となり、高パフォーマンスバッチ処理の基礎となります。また、以下例のように、Spring Batch Stepへ簡単にインジェクション出来ます。
Java Configuration
@Bean public JdbcCursorItemReader<CustomerCredit> itemReader() { return new JdbcCursorItemReaderBuilder<CustomerCredit>() .dataSource(this.dataSource) .name("creditReader") .sql("select ID, NAME, CREDIT from CUSTOMER") .rowMapper(new CustomerCreditRowMapper()) .build(); }
Additional Properties
Javaでカーソルオープンする際は多様なオプションがあり、JdbcCursorItemReaderにも設定可能な多数のプロパティが存在します。
Table 2. JdbcCursorItemReader Properties
| ignoreWarnings | SQLWarningsログ出力するか例外を発生させるか。デフォルトはtrue(warningsをログ出力) |
| fetchSize | JDBCドライバにDBからフェッチする行数のヒントを指定。ItemReaderで使用するResultSetが行を要求する時の行数。デフォルトは未指定。 |
| maxRows | 内部のResultSetが保持可能な最大行数。 |
| queryTimeout | ドライバがStatementをwaitする秒数。limitを超える場合、DataAccessExceptionをスローする。(詳細はドライバのドキュメントを参照) |
| verifyCursorPosition | ItemReaderで保持するのと同じResultSetをRowMapperに渡すため、そこでResultSet.next()を呼ぶことが可能であり、reader内部のカウントと食い違う可能性があります。このプロパティをtrueにすると、RowMapper呼び出し後にカーソル位置が異なる場合、例外をスローします。 |
| saveState | ItemStream#update(ExecutionContext)でExecutionContextにreaderのstateをセーブするかどうかの設定。デフォルト```true````。 |
| driverSupportsAbsolute | JDBCドライバがResultSetのabsolute rowをサポートするどうかを指定します。ResultSet.absolute()をサポートするJDBCドライバの場合trueを推奨します。大規模データセットを処理するstepが失敗する場合に特にパフォーマンス改善が見込めます。デフォルトはfalse |
| setUseSharedExtendedConnection | カーソルで使うコネクションを他の処理でも使うかどうか、つまり同一トランザクションを共有するような、を指定します。falseでは、カーソルは固有のコネクションでオープンし、以降のstep処理で開始するトランザクションには参加しません。trueでは、クローズと各コミット後の解放をしないようにDataSourceをExtendedConnectionDataSourceProxyでラップします。trueにする場合、カーソルオープンに使うstatementは'READ_ONLY'および'HOLD_CURSORS_OVER_COMMIT'オプションで生成します。これによりstep処理で実行するトランザクション開始とコミットでカーソルを開いたままに出来ます。この機能を使用するには、データベースが本機能をサポートし、JDBCドライバ 3.0以降の必要があります。デフォルトfalse。 |
HibernateCursorItemReader
SpringユーザがORMを使うかどうか、JdbcTemplateを使うかHibernateTemplateを使うのかに影響するような、重要な決定を下すのと同様、Spring Batchユーザにも同じ選択肢があります。HibernateCursorItemReaderはカーソルのHibernate版の実装です。バッチでHibernateを使うことには賛否があります。Hibernateは元々オンラインアプリケーション用に開発されてきたという点が大きく影響しています。しかし、だからバッチ処理には使えない、という意味にはなりません。問題解決にはスタンダードなsessionではなくStatelessSessionを使うのが手軽です。これはキャッシュとHiberanteが採用するdirty checkingを無くしたもので、バッチで何等かの問題を起こす可能性があります。statelessと通常のhibernate sesseionの詳細な違いについては、各バージョンのhibernateのドキュメントを参照してください。HibernateCursorItemReaderではHQLステートメントとSessionFactoryを渡すと、JdbcCursorItemReaderと同じようにreadごとに1アイテムが返されます。以下の例はJDBC readerのと同じ'customer credit'の設定です。
HibernateCursorItemReader itemReader = new HibernateCursorItemReader(); itemReader.setQueryString("from CustomerCredit"); //説明簡略化のため、sessionFactoryは定義済みとする。 itemReader.setSessionFactory(sessionFactory); itemReader.setUseStatelessSession(true); int counter = 0; ExecutionContext executionContext = new ExecutionContext(); itemReader.open(executionContext); Object customerCredit = new Object(); while(customerCredit != null){ customerCredit = itemReader.read(); counter++; } itemReader.close();
上記設定のItemReaderは、Cutomerテーブルに対するhibernateマッピングファイルが正しく作られていれば、JdbcCursorItemReaderで説明したの同様にCustomerCreditを返します。'useStatelessSession'プロパティのデフォルトはtrueですがOn/Offが可能なことを示す説明のために指定しています。また、内部的なカーソルのフェッチサイズをsetFetchSizeプロパティで設定可能な点も重要です。JdbcCursorItemReader同様、以下例のように、設定は単純です。
Java Configuration
@Bean public HibernateCursorItemReader itemReader(SessionFactory sessionFactory) { return new HibernateCursorItemReaderBuilder<CustomerCredit>() .name("creditReader") .sessionFactory(sessionFactory) .queryString("from CustomerCredit") .build(); }
StoredProcedureItemReader
場合によってはストアドプロシージャでカーソルのデータを取得する必要があります。StoredProcedureItemReaderはJdbcCursorItemReaderのような挙動をしますが、カーソル取得にクエリではなく、カーソルを返すストアドプロシージャを実行します。このストアドプロシージャは3つの異なる方法でカーソルを返します。
ResultSetを返す(SQL Server, Sybase, DB2, Derby, and MySQLを使用する場合)- 出力パラメータとしてref-cursorを返す(OracleやPostgreSQLを使う場合)
- ストアド関数呼び出しの戻り値
以下の例は前述の'customer credit'と同じものを使う設定です。
Java Configuration
@Bean public StoredProcedureItemReader reader(DataSource dataSource) { StoredProcedureItemReader reader = new StoredProcedureItemReader(); reader.setDataSource(dataSource); reader.setProcedureName("sp_customer_credit"); reader.setRowMapper(new CustomerCreditRowMapper()); return reader; }
上の例は結果を返すためのResultSetを返すためにストアドプロシージャを使用します(3つの方法の内1番目)。
ストアドプロシージャがref-cursor(2番目の方法)を返す場合、ref-cursorを返す出力パラメータのポジションを指定する必要があります。以下の例はref-cursorを最初のパラメータとして設定する方法です。
Java Configuration
@Bean public StoredProcedureItemReader reader(DataSource dataSource) { StoredProcedureItemReader reader = new StoredProcedureItemReader(); reader.setDataSource(dataSource); reader.setProcedureName("sp_customer_credit"); reader.setRowMapper(new CustomerCreditRowMapper()); reader.setRefCursorPosition(1); return reader; }
ストアドファンクションがカーソルを返す(3番目の方法)場合、"function"プロパティをtrueにします。デフォルトはfalseです。
Java Configuration
@Bean public StoredProcedureItemReader reader(DataSource dataSource) { StoredProcedureItemReader reader = new StoredProcedureItemReader(); reader.setDataSource(dataSource); reader.setProcedureName("sp_customer_credit"); reader.setRowMapper(new CustomerCreditRowMapper()); reader.setFunction(true); return reader; }
いずれの方法においても、RowMapperとDataSourceとプロシージャ名の定義が必要です。
ストアドプロシージャやファンクションがパラメータを取る場合、parametersで宣言と設定をします。以下はOracleの場合で、3つのパラメータを宣言しています。1つ目はref-cusorを返す出力パラメータで、2つ目と3つ目はINTEGERを取るパラメータです。
Java Configuration
@Bean public StoredProcedureItemReader reader(DataSource dataSource) { List<SqlParameter> parameters = new ArrayList<>(); parameters.add(new SqlOutParameter("newId", OracleTypes.CURSOR)); parameters.add(new SqlParameter("amount", Types.INTEGER); parameters.add(new SqlParameter("custId", Types.INTEGER); StoredProcedureItemReader reader = new StoredProcedureItemReader(); reader.setDataSource(dataSource); reader.setProcedureName("spring.cursor_func"); reader.setParameters(parameters); reader.setRefCursorPosition(1); reader.setRowMapper(rowMapper()); reader.setPreparedStatementSetter(parameterSetter()); return reader; }
パラメータ宣言に加えて、パラメータをセットするPreparedStatementSetter実装の指定も必要です。上記は上述のJdbcCursorItemReaderと同様の動作をします。Additional Propertiesも同様にStoredProcedureItemReaderに適用されます。
1.10.2. Paging ItemReader Implementations
結果グループを返す個々の問い合わせを複数回実行するデータベースカーソルを使う方法もあります。この結果グループをページと呼称します。個々の問い合わせには開始行番号とページの行数を指定します。
JdbcPagingItemReader
ページングするItemReaderの実装の一つがJdbcPagingItemReaderです。JdbcPagingItemReaderはPagingQueryProviderを必要とし、このクラスはページ内の行を取得するSQLクエリを作成する責務を持ちます。データベースはそれぞれ固有のページングを持つので、データベースに合わせたPagingQueryProviderを指定します。なお、SqlPagingQueryProviderFactoryBeanは使用するデータベースを自動検出して適切なPagingQueryProvider実装を決定します。これにより設定は簡素化されるので、このクラスを使うことを推奨します。
SqlPagingQueryProviderFactoryBeanにはselectと``fromが必要です。また、オプションでwhereも指定可能です。これらの句とsortKey```をSQLステートメントの構築に使います。
※ sortKeyがユニーク制約を持つ事は重要で、複数回ジョブ実行時にデータが無くならいことを保証します。
readerがオープンすると、他のItemReader同様にread呼び出しをすると1アイテムが返ります。この裏側では、返す行が必要になるとページングが発生します。
以下の設定例は以前に解説したカーソルベースのItemReaderと同じ'customer credit'を使います。
Java Configuration
@Bean public JdbcPagingItemReader itemReader(DataSource dataSource, PagingQueryProvider queryProvider) { Map<String, Object> parameterValues = new HashMap<>(); parameterValues.put("status", "NEW"); return new JdbcPagingItemReaderBuilder<CustomerCredit>() .name("creditReader") .dataSource(dataSource) .queryProvider(queryProvider) .parameterValues(parameterValues) .rowMapper(customerCreditMapper()) .pageSize(1000) .build(); } @Bean public SqlPagingQueryProviderFactoryBean queryProvider() { SqlPagingQueryProviderFactoryBean provider = new SqlPagingQueryProviderFactoryBean(); provider.setSelectClause("select id, name, credit"); provider.setFromClause("from customer"); provider.setWhereClause("where status=:status"); provider.setSortKey("id"); return provider; }
ここで設定したItemReaderはRowMapper(必須)でCustomerCreditを返します。'pageSize'プロパティは個々のクエリ実行時にデータベースから読み込むエンティティ数を指定します。
'parameterValues'プロパティにはクエリのパラメータのMapを指定します。whereで名前付きパラメータを使う場合、keyをパラメータの名前と一致させます。従来からの'?'パラメータを使う場合、keyは1から始めるプレースホルダー番号と一致させます。
JpaPagingItemReader
ページングするItemReaderの実装のもう一つはJpaPagingItemReaderです。JPAにはHibernateのStatelessSessionに類する機能が無いため、JPA仕様が提供する範囲の機能を使う必要があります。JPAはページングをサポートするため、バッチ処理にJPAを使うのは自然な選択です。ページが読み込まれると、そのエンティティはdetachしてpersistence contextはクリアし、これによりエンティティはページ処理後にGC可能になります。
JpaPagingItemReaderにはJPQLを宣言してEntityManagerFactoryを渡します。他のItemReader同様にreadで1アイテム返します。この裏側では、返すエンティティが必要になるとページングが発生します。以下の設定例は以前に解説したJDBC readerと同じ'customer credit'を使います。
Java Configuration
@Bean public JpaPagingItemReader itemReader() { return new JpaPagingItemReaderBuilder<CustomerCredit>() .name("creditReader") .entityManagerFactory(entityManagerFactory()) .queryString("select c from CustomerCredit c") .pageSize(1000) .build(); }
ここで設定したItemReaderは上で解説したJdbcPagingItemReaderと同様にCustomerCreditを返します。なお、CustomerCreditをJPAアノテーションかORMマッピングファイルで正しく設定しているとします。'pageSize'プロパティは個々のクエリ実行が返すエンティティ数を指定します。
1.10.3. Database ItemWriters
フラットファイルおよびXMLファイルは固有のItemWriterを持ちますが、これはデータベースの世界とは同等ではありません。トランザクションはすべてのケースで必要な機能を提供します。ファイルのItemWriter実装はトランザクションであるかのように振る舞う必要があり、書き込みアイテムのトラッキングと適切なタイミングでフラッシュかクリアをします。データベースではこれは不要で、これはwriteがトランザクション内で行われるためです。ユーザはItemWriterを実装するDAOを作成するか、汎用書き込み処理をするカスタムItemWriterの一つを使用します。どちらの方法でも問題なく動作します。一つ注意する点としてはパフォーマンスとバッチ出力が提供するエラーハンドリング機能です。ItemWriterにhiberanateを使うのは一般的ですがJDBCのバッチモードと同様の問題が発生する可能性があります。バッチ化したデータベース出力は、フラッシュに注意してデータにエラーが無ければ、固有の欠点はありません。しかし、書き込み中のエラー発生は、以下図のように、例外を引き起こしたアイテムを知る方法が無いし、even if any individual item was responsibleなので、混乱を招く可能性があります。
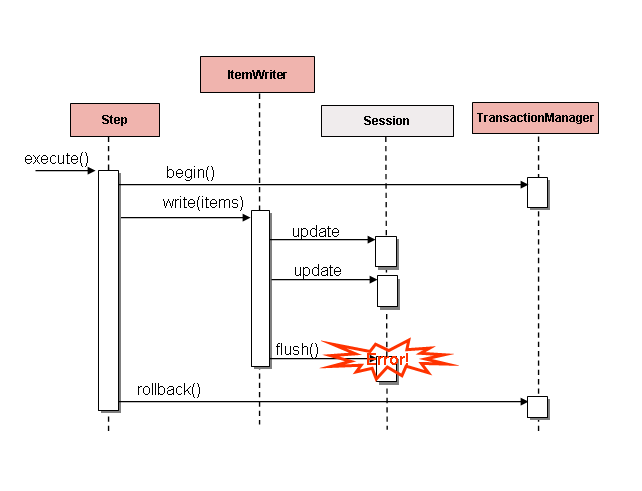
Figure 4. Error On Flush
書き込み前にバッファするアイテムは、コミット前にバッファがフラッシュするまでエラーはスローされません。例えば、chunkで20アイテム書き込むとして、15番目のアイテムがDataIntegrityViolationExceptionをスローします。実際に書き込むまでエラー発生を知る方法が無いので、Stepでは全20アイテムの書き込みが正常終了と見なします。Session#flush()すると、バッファが空になり例外がヒットします。この時点では`stepに出来ることは何もありません。トランザクションはロールバックが必須となります。通常、この例外はアイテムのスキップ(skip/retryポリシーに依る)となり、再度の書き込みはしません。しかし、バッチにおいては、問題を引き起こしたアイテムを知る方法がありません。エラー発生時にバッファ全体を書き込みます。これを解消する唯一の方法は、以下のように、1アイテムごとにフラッシュします。
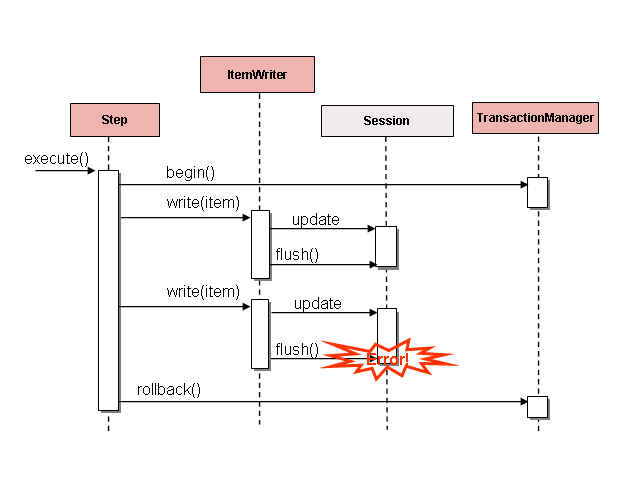
Figure 5. Error On Write
これも、特にHibernateを使う場合では、一般的なパターンで、ItemWriter実装のシンプルガイドラインではwrite()ごとにフラッシュします。これにより確実にアイテムスキップが可能となります, with Spring Batch internally taking care of the granularity of the calls to ItemWriter after an error.
1.11. Reusing Existing Services
バッチシステムは他のアプリケーションと組み合わせて使う場合があります。よくあるのはオンラインシステムで、 but it may also support integration or even a thick client application by moving necessary bulk data that each application style uses. よって、バッチジョブでも既存DAOやサービスを使いまわしたいことが良くあります。Springコンテナは必要クラスをインジェクションすることでこれを簡単に実装できます。しかし、既存サービスをItemReaderやItemWriterとして振る舞わせたいケースがあり、これはSpring Batchクラスの依存性を満たすか、サービスそれ自身をstepのItemReaderにします。各サービスをラップするアダプターを作るのは簡単ですが、これは良くあるパターンなので、Spring BatchはItemReaderAdapterとItemWriterAdapterの実装を用意しています。両クラスとも一般的なデリゲートパターンを実装しており設定は簡単です。以下はItemReaderAdapterの例です。
Java Configuration
@Bean public ItemReaderAdapter itemReader() { ItemReaderAdapter reader = new ItemReaderAdapter(); reader.setTargetObject(fooService()); reader.setTargetMethod("generateFoo"); return reader; } @Bean public FooService fooService() { return new FooService(); }
重要な点としてtargetMethodはreadと同じ仕様にする必要があります。つまり返すデータが無い場合nullを返します。もしくはObjectを返します。ItemWriterの実装次第では、フレームワークが処理終了を検出するのを妨げる何かがあると、無限ループや不正確な失敗が発生します。以下はItemWriterAdapterの例です。
Java Configuration
@Bean public ItemWriterAdapter itemWriter() { ItemWriterAdapter writer = new ItemWriterAdapter(); writer.setTargetObject(fooService()); writer.setTargetMethod("processFoo"); return writer; } @Bean public FooService fooService() { return new FooService(); }
1.12. Validating Input
本チャプターでは入力をパースする各種の方法について解説してきました。それぞれ主要の実装は既定の形式('well-formed')でなければ例外をスローします。FixedLengthTokenizerデータ範囲がおかしければ例外をスローします。また、RowMapperやFieldSetMapperのインデックスにアクセスが存在していなかったり期待と異なるフォーマットだと例外をスローします。これらの例外はreadを返す前にスローします。しかし、返すアイテムがvalidかどうかは扱いません。たとえば、フィールドの一つが年齢だとして、明らかに負の値はありえません。存在してかつ数値であれば正しくパースは可能ですが、例外はスローしません。validation frameworksはすでに多数存在するのでSpring Batch固有のものは提供しません。代わりに、シンプルなインタフェースValidatorがあり、任意のフレームワークがこれを実装します。
public interface Validator<T> { void validate(T value) throws ValidationException; }
オブジェクトがinvalidなら例外をスローしてそうでなければ通常通り返します。Spring BatchはValidatingItemProcessorを提供します。
Java Configuration
@Bean public ValidatingItemProcessor itemProcessor() { ValidatingItemProcessor processor = new ValidatingItemProcessor(); processor.setValidator(validator()); return processor; } @Bean public SpringValidator validator() { SpringValidator validator = new SpringValidator(); validator.setValidator(new TradeValidator()); return validator; }
また、Bean Validation API (JSR-303) でアイテムをvalidationするにはBeanValidatingItemProcessorが使えます。
class Person { @NotEmpty private String name; public Person(String name) { this.name = name; } public String getName() { return name; } public void setName(String name) { this.name = name; } }
BeanValidatingItemProcessor beanをアプリケーションコンテキスに宣言してchunk stepにprocessorとして登録することでアイテムをvalidateします。
@Bean public BeanValidatingItemProcessor<Person> beanValidatingItemProcessor() throws Exception { BeanValidatingItemProcessor<Person> beanValidatingItemProcessor = new BeanValidatingItemProcessor<>(); beanValidatingItemProcessor.setFilter(true); return beanValidatingItemProcessor; }
1.13. Preventing State Persistence
デフォルトではすべてのItemReader, ItemWriterはコミット前にExecutionContextに現在の状態を保存しますが、これが望ましい振る舞いではない場合があります。たとえば、process indicatorで再実行可能('rerunnable')なdatabse readerを作成する場合です。これは入力データに処理済みかどうかを示すのカラムを設けます。あるレコードが読み込み(や書き込み)したら処理済みフラグをfalseからtrueにします。SQLステートメントはwhere PROCESSED_IND = falseなどを持たせ、リスタートの場合に未処理レコードのみ返すようにします。この場合、現在行番号などはリスタートに無関係なので、状態を持つ必要はありません。このため、readerとwriterには'saveState'プロパティがあります。
Java Configuration
@Bean public JdbcCursorItemReader playerSummarizationSource(DataSource dataSource) { return new JdbcCursorItemReaderBuilder<PlayerSummary>() .dataSource(dataSource) .rowMapper(new PlayerSummaryMapper()) .saveState(false) .sql("SELECT games.player_id, games.year_no, SUM(COMPLETES)," + "SUM(ATTEMPTS), SUM(PASSING_YARDS), SUM(PASSING_TD)," + "SUM(INTERCEPTIONS), SUM(RUSHES), SUM(RUSH_YARDS)," + "SUM(RECEPTIONS), SUM(RECEPTIONS_YARDS), SUM(TOTAL_TD)" + "from games, players where players.player_id =" + "games.player_id group by games.player_id, games.year_no") .build(); }
上で設定するItemReaderはいずれの実行においてもExecutionContextにエントリを作りません。
1.14. Creating Custom ItemReaders and ItemWriters
これまで、このチャプターではSpring Batchの読み込みと書き込みの基本仕様と汎用の実装クラスを解説してきました。しかし、これらはすべて汎用品であり、そのクラスではカバーできないケースは多数存在します。このセクションでは、シンプルなケースを通して、カスタムのItemReaderとItemWriterの作成と仕様の正しい実装方法について解説します。readerやwriterをリスタート可能にするにはItemReaderに加えてItemStreamも実装します。
1.14.1. Custom ItemReader Example
解説のために、指定リストから読み込むシンプルなItemReaderを作ります。ItemReaderとreadの基本的な仕様の実装かあ始めます。
public class CustomItemReader<T> implements ItemReader<T>{ List<T> items; public CustomItemReader(List<T> items) { this.items = items; } public T read() throws Exception, UnexpectedInputException, NonTransientResourceException, ParseException { if (!items.isEmpty()) { return items.remove(0); } return null; } }
上のクラスはアイテムのリストを指定して1アイテムを返し、リストからそのアイテムを削除します。リストが空になると、nullを返すことで、ItemReaderの最も基本的な仕様を満たします。テストコードは以下になります。
List<String> items = new ArrayList<String>(); items.add("1"); items.add("2"); items.add("3"); ItemReader itemReader = new CustomItemReader<String>(items); assertEquals("1", itemReader.read()); assertEquals("2", itemReader.read()); assertEquals("3", itemReader.read()); assertNull(itemReader.read());
Making the ItemReader Restartable
次にItemReaderをリスタート可能にします。現状では、処理中断して再開すると、ItemReaderは最初から開始します。これが妥当な事も多いですが、場合によっては中断箇所からリスタートするバッチジョブが望ましい事があります。キーポイントはreaderがstatefulかstatelessかす。stateless readerはrestartabilityの懸念は無いですが、statefulはリスタートで最終状態を再構築の必要があります。このため、出来る限り、カスタムreaderをstatelessにする事を推奨します。これによりrestartabilityの懸念が無くなります。
状態を保存する場合、ItemStreamを使います。
public class CustomItemReader<T> implements ItemReader<T>, ItemStream { List<T> items; int currentIndex = 0; private static final String CURRENT_INDEX = "current.index"; public CustomItemReader(List<T> items) { this.items = items; } public T read() throws Exception, UnexpectedInputException, ParseException, NonTransientResourceException { if (currentIndex < items.size()) { return items.get(currentIndex++); } return null; } public void open(ExecutionContext executionContext) throws ItemStreamException { if(executionContext.containsKey(CURRENT_INDEX)){ currentIndex = new Long(executionContext.getLong(CURRENT_INDEX)).intValue(); } else{ currentIndex = 0; } } public void update(ExecutionContext executionContext) throws ItemStreamException { executionContext.putLong(CURRENT_INDEX, new Long(currentIndex).longValue()); } public void close() throws ItemStreamException {} }
ItemStreamのupdateの度にItemReaderの現在インデックスを'current.index'キーでExecutionContextに保存します。ItemStream openでは、ExecutionContextにキーでエントリがあるかどうかをチェックします。もしキーが有れば現在インデックスを移動します。これはかなりシンプルな例ですが、仕様を満たしています。
ExecutionContext executionContext = new ExecutionContext(); ((ItemStream)itemReader).open(executionContext); assertEquals("1", itemReader.read()); ((ItemStream)itemReader).update(executionContext); List<String> items = new ArrayList<String>(); items.add("1"); items.add("2"); items.add("3"); itemReader = new CustomItemReader<String>(items); ((ItemStream)itemReader).open(executionContext); assertEquals("2", itemReader.read());
ItemReaders実装の多くは固有のリスタートロジックを持っています。例えばJdbcCursorItemReaderはカーソルの最終処理行のrow IDを保存します。
ExecutionContextのキーはちょっとした程度のものでは無い点に注意してください。StepのすべてのItemStreamsで同一のExecutionContextを使うためです。基本的には、単にクラス名がプレフィクスのキーで十分に一意になります。しかし、まれに、同一stepに同一のItemStreamがある場合(出力に2ファイル必要な場合こうなる)があり、ユニークにするにはもう一工夫が必要です。このため、Spring BatchのItemReaderとItemWriter実装の多くはキー名をオーバーライドするsetName()を持っています。
1.14.2. Custom ItemWriter Example
カスタムItemWriterの実装は様々な点でItemReaderと同じですが、but differs in enough ways as to warrant its own example. しかし、restartabilityの付与は基本的に変わらないので、ここの例では扱いません。ItemReader同様、サンプルをなるべくシンプルにするためにListを使います。
public class CustomItemWriter<T> implements ItemWriter<T> { List<T> output = TransactionAwareProxyFactory.createTransactionalList(); public void write(List<? extends T> items) throws Exception { output.addAll(items); } public List<T> getOutput() { return output; } }
Making the ItemWriter Restartable
ItemWriterをリスタート可能にするには、ItemReaderと同様のプロセスを踏み、execution contextを同期化するためにItemStreamを追加して実装します。サンプルでは、処理アイテム数カウントとフッター行にこれを追加することになるでしょう。これを実装する必要が出た場合ItemWriterにItemStreamを実装し、このItemStreamを再オープン時にexecution contextからカウンタを再構築します。
実際には、別のwriterにデリゲートするItemWriters自身もリスタート可能(例えばファイル書き込み時など)だとか、トランザクショナルなリソースに書き込むためにリスタートの必要が無いつまりステートレス、な事があります。ステートフルなwriterを使う場合ItemWriterと同様にItemStreamも注意して実装してくだい。こうしたwriterのクライアントはItemStreamな事にも注意を払う必要があり、設定でstreamとして登録する必要がある場合があります。
1.15. Item Reader and Writer Implementations
ここでは、これまでのセクションで解説していないreaderとwriterの実装について紹介します。
1.15.1. Decorators
既存のItemReaderに特殊な振る舞いを追加したい場合があります。Spring BatchはItemReaderおよびItemWriter実装に振る舞いを追加するデコレータを用意しています。
Spring Batchには以下のデコレータがあります。
- SynchronizedItemStreamReader
- SingleItemPeekableItemReader
- MultiResourceItemWriter
- ClassifierCompositeItemWriter
- ClassifierCompositeItemProcessor
SynchronizedItemStreamReader
ItemReaderがスレッドセーフでは無い場合、Spring BatchのSynchronizedItemStreamReaderにより、ItemReaderをスレッドセーフに出来ます。Spring BatchはSynchronizedItemStreamReaderを生成するSynchronizedItemStreamReaderBuilderを用意しています。
SingleItemPeekableItemReader
Spring BatchにはItemReaderにpeekメソッドを追加するデコレータがあります。peekメソッドは1つ先のアイテムを読み込めます。peedを繰り返し読んでも同一アイテムが返され、そのアイテムは次回のreadメソッド呼び出し結果と同一です。Spring BatchはSingleItemPeekableItemReaderを生成するSingleItemPeekableItemReaderBuilderを用意しています。
※ SingleItemPeekableItemReaderのpeekメソッドは非スレッドセーフで、これはマルチスレッドでpeekを保証できないと考えられるためです。peekしたスレッドのうち1つだけが次回の読み込みでそのアイテムを読み込む可能性があります。
MultiResourceItemWriter
MultiResourceItemWriterはResourceAwareItemWriterItemStreamをラップし、現在のリソースに書き込んだアイテム数がitemCountLimitPerResourceを超える場合に次の出力リソースを新規作成します。Spring BatchはMultiResourceItemWriterを生成するMultiResourceItemWriterBuilderを用意しています。
ClassifierCompositeItemWriter
ClassifierCompositeItemWriterは、指定するClassifier実装のルーターパターンに基づき、各アイテムごとにItemWriter実装コレクションのうち1つを呼び出します。すべてのデリゲート先がスレッドセーフであればこの実装はスレッドセーフになります。Spring BatchはClassifierCompositeItemWriterを生成するClassifierCompositeItemWriterBuilderを用意しています。
ClassifierCompositeItemProcessor
ClassifierCompositeItemProcessorは、指定するClassifier実装のルーターパターンに基づき、ItemProcessor実装コレクションのうち1つを呼び出すItemProcessorです。Spring BatchはClassifierCompositeItemProcessorを生成するClassifierCompositeItemProcessorBuilderを用意しています。
1.15.2. Messaging Readers And Writers
Spring Batchではメッセージングシステム用のreaderとwriterを用意しています。
AmqpItemReader
AmqpItemReaderはexchangeからメッセージを受信したり変換するのにAmqpTemplateを使うItemReaderです。Spring BatchはAmqpItemReaderを生成するAmqpItemReaderBuilderを用意しています。
AmqpItemWriter
AmqpItemWriterはAMQP exchangeへメッセージ送信するのにAmqpTemplateを使うItemWriterです。AmqpTemplateにnama未指定の場合はnameless exchangeにメッセージを送信します。Spring BatchはAmqpItemWriterを生成するAmqpItemWriterBuilderを用意しています。
JmsItemReader
JmsItemReaderはJmsTemplateを使用するJMS用のItemReaderです。テンプレートにはデフォルトのdestinationを持たせてくてださい。read()メソッドでのアイテム取得に使います。Spring BatchはJmsItemReaderを生成するJmsItemReaderBuilderを用意しています。
JmsItemWriter
JmsItemWriterはJmsTemplateを使用するJMS用のItemWriterです。テンプレートにはデフォルトのdestinationを持たせてくてださい。write(List)でのアイテム送信に使います。Spring BatchはJmsItemWriterを生成するJmsItemWriterBuilderを用意しています。
1.15.3. Database Readers
Spring Batchは以下のdatabase readerを提供します。
- Neo4jItemReader
- MongoItemReader
- HibernateCursorItemReader
- HibernatePagingItemReader
- RepositoryItemReader
Neo4jItemReader
Neo4jItemReaderはpaging techniqueを使用してgraph database Neo4jからオブジェクトを読み込むItemReaderです。Spring BatchはNeo4jItemReaderを生成するNeo4jItemReaderBuilderを用意しています。
MongoItemReader
MongoItemReaderはpaging techniqueを使用してMongoDBからドキュメントを読み込むItemReaderです。Spring BatchはMongoItemReaderを生成するMongoItemReaderBuilderを用意しています。
HibernateCursorItemReader
HibernateCursorItemReaderはHibernateベースでDBレコードを読み込むItemStreamReaderです。HQLクエリを実行すると、初期化し、read()が呼ばれると結果をイテレートし、現在行に対応するオブジェクトを逐次返します。Spring BatchはHibernateCursorItemReaderを生成するHibernateCursorItemReaderBuilderを用意しています。
HibernatePagingItemReader
HibernatePagingItemReaderはHibernateベースでDBレコードを読み込むItemReaderで、一度に固定数アイテム読み込みます。Spring BatchはHibernatePagingItemReaderを生成するHibernatePagingItemReaderBuilderを用意しています。
RepositoryItemReader
RepositoryItemReaderはPagingAndSortingRepositoryを使用してレコードを読み込むItemReaderです。Spring BatchはRepositoryItemReaderを生成するRepositoryItemReaderBuilderを用意しています。
1.15.4. Database Writers
Spring Batchは以下のdatabase writerを提供します。
- Neo4jItemWriter
- MongoItemWriter
- RepositoryItemWriter
- HibernateItemWriter
- JdbcBatchItemWriter
- JpaItemWriter
- GemfireItemWriter
Neo4jItemWriter
Neo4jItemWriterはNeo4jデータベースに書き込むItemWriterの実装です。Spring BatchはNeo4jItemWriterを生成するNeo4jItemWriterBuilderを用意しています。
MongoItemWriter
MongoItemWriterはSpring DataのMongoOperationsの実装を使用してMongoDBに書き込むItemWriterの実装です。Spring BatchはMongoItemWriterを生成するMongoItemWriterBuilderを用意しています。
RepositoryItemWriter
RepositoryItemWriterはSpring DataのCrudRepository用のItemWriterラッパーです。Spring BatchはRepositoryItemWriterを生成するRepositoryItemWriterBuilderを用意しています。
HibernateItemWriter
HibernateItemWriterは現在のHibernate sessionに居ないエンティティのsaveやupdateをするItemWriterです。Spring BatchはHibernateItemWriterを生成するHibernateItemWriterBuilderを用意しています。
JdbcBatchItemWriter
JdbcBatchItemWriterは全アイテムのステートメントをバッチ実行するのにNamedParameterJdbcTemplateの機能を使います。Spring BatchはJdbcBatchItemWriterを生成するJdbcBatchItemWriterBuilderを用意しています。
JpaItemWriter
JpaItemWriterは現在の永続化コンテキストに居ないエンティティをmergeするのにJPAのEntityManagerFactoryを使うItemWriterです。Spring BatchはJpaItemWriterを生成するJpaItemWriterBuilderを用意しています。
GemfireItemWriter
GemfireItemWriterはkey/valueでGemFireにアイテムを格納するのにGemfireTemplateを使うItemWriterです。Spring BatchはGemfireItemWriterを生成するGemfireItemWriterBuilderを用意しています。
1.15.5. Specialized Readers
Spring Batchには以下の特化reader(specialized readers)があります。
LdifReader
LdifReaderはLDIF(LDAP Data Interchange Format)をResourceから読み込み・パースしてreadでLdapAttributeを返します。Spring BatchはLdifReaderを生成するLdifReaderBuilderを用意しています。
MappingLdifReader
MappingLdifReaderはLDIF (LDAP Data Interchange Format)をResourceから読み込み・パースしてLDIFレコードをPOJOにマッピングします。readはPOJOを返します。Spring BatchはMappingLdifReaderを生成するMappingLdifReaderBuilderを用意しています。
1.15.6. Specialized Writers
Spring Batchには以下の特化writerがあります。
SimpleMailMessageItemWriter
SimpleMailMessageItemWriterはメール送信するItemWriterです。実際のメール送信はMailSenderにデリゲートします。Spring BatchはSimpleMailMessageItemWriterを生成するSimpleMailMessageItemWriterBuilderを用意しています。
1.15.7. Specialized Processors
Spring Batchには以下の特化processorがあります。
ScriptItemProcessor
ScriptItemProcessorはスクリプトに処理したいアイテムを渡し、processorの戻り値がスクリプトの結果になります。Spring BatchはMappingLdifReaderを生成するMappingLdifReaderBuilderを用意しています。