https://docs.spring.io/spring-batch/4.1.x/reference/html/readersAndWriters.html#readersAndWriters
https://qiita.com/kagamihoge/items/12fbbc2eac5b8a5ac1e0 俺の訳一覧リスト
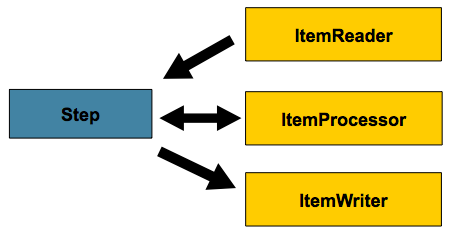
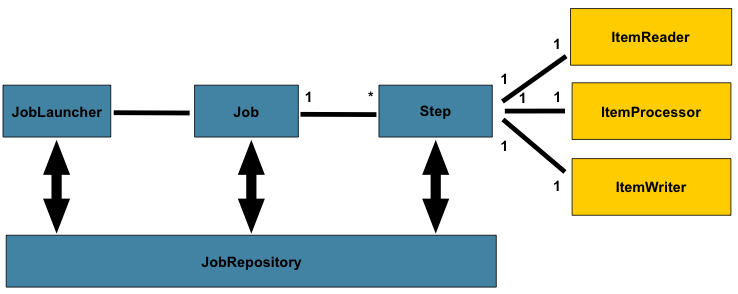
1. ItemReaders and ItemWriters
すべてのバッチ処理は、大規模データの読み込み・何らかの計算あるいは変換処理・結果の書き込み、というシンプルな形で説明が可能です。Spring Batchはバルク読み込みと書き込みを実行する3つの中核インタフェース、ItemReader, ItemProcessor, ItemWriter、を用意しています。
1.1. ItemReader
コンセプトはシンプルですが、ItemReaderは多数の異なる種類の入力からデータを受け取るクラスです。よくある例は以下の通りです。
- フラットファイル: フラットファイルのitem readerはフラットファイルからデータ行を読み込みます。このファイルは基本的にレコード定義を、各フィールドはファイルの固定位置で定義するか、なんらかの特殊文字(カンマ)による区切り、で行います。
- XML: XMLの
ItemReadersは、パース処理するテクノロジとは独立してXMLを処理し、オブジェクトのマッピングとvalidateをします。入力データはXSDスキーマに対するXMLファイルvalidationが可能です。 - Database: DBリソースのresultsetからprocessに回すオブジェクトにマッピングします。デフォルトのSQL
ItemReader実装は戻りオブジェクトにRowMapperを実行し、リスタートする場合はカレントの行をトラッキングし、基本的な統計を保存し、後述するトランザクション機能を提供します。
様々な用途が考えられますが、このチャプターでは基本的な事柄に焦点をあてます。利用可能なすべてのItemReader実装のリストはAppendix Aを参照してください。
ItemReaderは、以下のインタフェース定義のように、汎用入力操作用の基礎的インタフェースです。
public interface ItemReader<T> { T read() throws Exception, UnexpectedInputException, ParseException, NonTransientResourceException; }
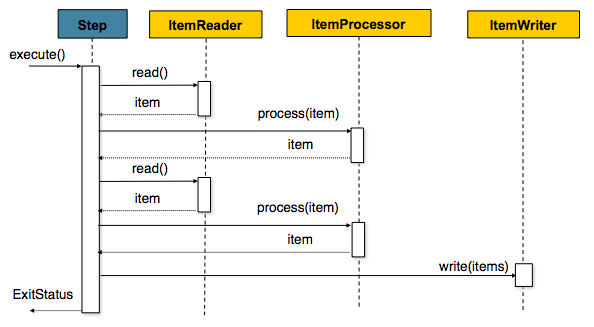
readメソッドはItemReaderの中核を定義しています。このメソッドは1つのitemを返すか、これ以上読み込みものが無い場合はnullを返します。itemは、ファイルの1行、DBの1行、XMLの1要素、を表します。これらのitemは扱いやすいドメインオブジェクト(Trade, Fooなど)に基本的には変換しますが、必須ではありません。
ItemReaderの実装は基本的には単方向のみです。ただし、基底リソースがtransactional(JMSキューなど)の場合、ロールバック発生時のその次にread呼び出しをすると同一のlogical itemを返す可能性があります。また、ItemReaderで処理するアイテムが無いけど例外をスローしないケースは一考の余地があります。たとえば、DBのItemReaderのクエリが0件の場合、readの初回呼び出しでnullを返します。
1.2. ItemWriter
ItemWriterは機能的にはItemReaderと似ていますがそれとは逆の操作をします。何らかのリソースを、配置・open・closeが必要な点は同じで、読み込みではなく書き込む点が異なります。DBやキューの場合、行う操作は、insert, update, sendになります。出力のシリアライズフォーマットはバッチジョブそれぞれ固有のものになります。
ItemReader同様ItemWriterは、以下のような、極めて汎用的なインタフェース定義です。
public interface ItemWriter<T> { void write(List<? extends T> items) throws Exception; }
ItemReaderのread同様、writeがItemWriterの振る舞いの基礎を提供します。open状態のwriterに渡されるitemのリストを書き込みます。基本的に、itemは複数まとめて('batched' together)chunkに入れて出力するという想定なので、インタフェースはwriter自身でitemを作成するのではなく、itemのリストを受け取ります。リストの書き込み後、writeメソッドを返す前に、状況に応じたflushを実行します。例えば、Hibernate DAOに書き込む場合、各アイテムごとに複数回書き込みを実行します。その後writerはreturn前にhibernate sessionのflushを呼び出します。
1.3. ItemProcessor
ItemReaderとItemWriterはここに書きたいタスクがある場合には有用ですが、書き込む前に実行したいビジネスロジックとは何でしょうか。書き込みと読み込みの両方で可能な一つのやり方にcomposite patternがあります。これは、別のItemWriterを持つItemWriterか、もしくは、別のItemReaderを持つItemReaderです。以下はその例です。
public class CompositeItemWriter<T> implements ItemWriter<T> { ItemWriter<T> itemWriter; public CompositeItemWriter(ItemWriter<T> itemWriter) { this.itemWriter = itemWriter; } public void write(List<? extends T> items) throws Exception { //Add business logic here itemWriter.write(items); } public void setDelegate(ItemWriter<T> itemWriter){ this.itemWriter = itemWriter; } }
上のクラスは、何らかのビジネスロジック実行後に、別のItemWriterにデリゲートします。このパターンは同様にItemReaderでも使用可能で、メインとなるItemReaderの入力を基にして更に別の参照データを得るような場合に使えます。write呼び出しを制御したい場合にも有用です。ただし、実際の書き込み前にアイテムを変換しておきたい場合、そのクラス自身ではwriteの必要はありません。そこではただ単にアイテムの修正のみ行います。この場合、Spring Batchの、以下インフェース定義を持つItemProcessorを使います。
public interface ItemProcessor<I, O> { O process(I item) throws Exception; }
ItemProcessorはシンプルです。1つのオブジェクトを与え、変換して返します。入出力のオブジェクトは同一型になる場合もならない場合もあります。ビジネスロジックはprocess内で適用する点と、その中身はロジックを作成する開発者に完全に委ねられている、という点が重要です。ItemProcessorはstepに直接ワイヤリングできます。たとえば、ItemReaderがFooクラスで読み込んで書き込み前にBarに変換する必要がある、とします。以下は変換を実行するItemProcessorの例です。
public class Foo {} public class Bar { public Bar(Foo foo) {} } public class FooProcessor implements ItemProcessor<Foo,Bar>{ public Bar process(Foo foo) throws Exception { // FooからBarへのシンプルな変換 return new Bar(foo); } } public class BarWriter implements ItemWriter<Bar>{ public void write(List<? extends Bar> bars) throws Exception { //barsの書き込み } }
上の例では、Foo, Barのクラスがあり、ItemProcessorを実装するFooProcessorがあります。変換はシンプルですが、これ以外の型へ変換することも可能です。BarWriterはBarオブジェクトを書き込み、これ以外の型が来る場合は例外をスローします。同じく、FooProcessorはFoo以外の場合に例外をスローします。FooProcessorは以下例のようにStepにインジェクションします。
Java Configuration
@Bean public Job ioSampleJob() { return this.jobBuilderFactory.get("ioSampleJOb") .start(step1()) .end() .build(); } @Bean public Step step1() { return this.stepBuilderFactory.get("step1") .<String, String>chunk(2) .reader(fooReader()) .processor(fooProcessor()) .writer(barWriter()) .build(); }
1.3.1. Chaining ItemProcessors
大抵のケースで変換は一つで十分ですが、複数のItemProcessor実装を一緒に実行したい場合はどうでしょうか。前に開設したcomposite patternで実現可能です。FooからBarに変換し、それからFooBarに変換して書き込む例は以下です。
public class Foo {} public class Bar { public Bar(Foo foo) {} } public class Foobar { public Foobar(Bar bar) {} } public class FooProcessor implements ItemProcessor<Foo,Bar>{ public Bar process(Foo foo) throws Exception { //Perform simple transformation, convert a Foo to a Bar return new Bar(foo); } } public class BarProcessor implements ItemProcessor<Bar,Foobar>{ public Foobar process(Bar bar) throws Exception { return new Foobar(bar); } } public class FoobarWriter implements ItemWriter<Foobar>{ public void write(List<? extends Foobar> items) throws Exception { //write items } }
FooProcessorとはBarProcessorは、以下例のように、結果としてFoobar```を返します。
CompositeItemProcessor<Foo,Foobar> compositeProcessor =
new CompositeItemProcessor<Foo,Foobar>();
List itemProcessors = new ArrayList();
itemProcessors.add(new FooTransformer());
itemProcessors.add(new BarTransformer());
compositeProcessor.setDelegates(itemProcessors);
先の例同様に、composite processorもStepに設定します。
Java ConfigurationStepListener
@Bean public Job ioSampleJob() { return this.jobBuilderFactory.get("ioSampleJob") .start(step1()) .end() .build(); } @Bean public Step step1() { return this.stepBuilderFactory.get("step1") .<String, String>chunk(2) .reader(fooReader()) .processor(compositeProcessor()) .writer(foobarWriter()) .build(); } @Bean public CompositeItemProcessor compositeProcessor() { List<ItemProcessor> delegates = new ArrayList<>(2); delegates.add(new FooProcessor()); delegates.add(new BarProcessor()); CompositeItemProcessor processor = new CompositeItemProcessor(); processor.setDelegates(delegates); return processor; }
1.3.2. Filtering Records
item processorの良くある使い方の一つはItemWriterに渡す前にレコードをフィルタリングします。フィルタはスキップとは異なるアクションです。スキップはレコードがinvalidなことを示し、一方、フィルタは書き込まないレコードを意味します。
例えば、三種の異なるタイプのレコード、挿入・更新・削除、を持つファイルを読むバッチジョブを考えます。対象システムでレコード削除が未サポートの場合、削除レコードはItemWriterには送りたくありません。しかし、レコード自体は不正データでは無いので、スキップではなくフィルタをかけたいと考えます。この結果、ItemWriterは挿入・更新レコードのみ受け取ります。
レコードをフィルタするには、ItemProcessorでnullを返します。フレームワークは戻り値nullがあるとItemWriterに渡すレコードリストにそのアイテムを追加しません。ItemProcessorの例外スローはスキップになります。
1.3.3. Fault Tolerance
chunkをロールバックすると、読み込みでキャッシュしたアイテムのreprocessが可能です。stepにfault tolerant(skipやretry処理)を設定する場合、ItemProcessorはべき等に実装します。基本的には、ItemProcessorで入力アイテムは一切変更せず、変更は結果となるインスタンスにだけ行います。
1.4. ItemStream
ItemReadersとItemWritersはそれぞれ固有の役割を持ちますが、両者に共通な役割のインタフェースがあります。基本的に、これは、バッチジョブのscopeの一部となり、readerとwriterでopen,closeをし、永続化状態のメカニズムを必要とします。ItemStreamは以下のインタフェースを提供します。
public interface ItemStream { void open(ExecutionContext executionContext) throws ItemStreamException; void update(ExecutionContext executionContext) throws ItemStreamException; void close() throws ItemStreamException; }
各メソッドの説明の前に、ExecutionContextについて触れます。ItemStreamも実装するItemReaderのクライアントはread前にopenを呼び出し、ファイルなど何らかのリソースのopenやコネクション取得を行います。同様の制限がItemWriter実装にも適用されます。Chapter 2で触れたように、ExecutionContextに再開用データがある場合、初期状態ではない位置からItemReaderやItemWriterを開始するためにそのデータを用います。逆に、openしたリソースの安全な解放を保証するべくcloseを呼びます。updateは現在保持している状態をExecutionContextにロードするために呼ばれます。現在の状態をコミット前にDBへの永続化を保証するため、コミット前に呼ばれます。
特殊な場合としてItemStreamのクライアントがStepの場合、ExecutionContextが各StepExecutionで作成され、ユーザはexecutitonの状態を格納でき、同一のJobInstanceで再開する場合はその状態を返します。Quartzに詳しい場合は、QuartsのJobDataMapに良く似たセマンティクスになっています。
1.5. The Delegate Pattern and Registering with the Step
CompositeItemWriterは、Spring Batchの共通パターンの一つ、delegation patternの例です。委譲先はStepListenerなどののコールバックインタフェースを実装する場合があります。そのインタフェースを実装し、かつ、JobのStepの一部としてSpring Batch Coreと連携させる場合、Stepに明示的な登録が必要となる場合がほとんどです。reader, writer, processorはStepに直接ワイヤリングすると、ItemStreamやStepListenerを実装している場合、自動登録されます。しかし、Stepは委譲先を関知しないため、以下例のように、これらをlistenerやstreamとしてインジェクションする必要があります。
Java ConfigurationStepListener
@Bean public Job ioSampleJob() { return this.jobBuilderFactory.get("ioSampleJob") .start(step1()) .end() .build(); } @Bean public Step step1() { return this.stepBuilderFactory.get("step1") .<String, String>chunk(2) .reader(fooReader()) .processor(fooProcessor()) .writer(compositeItemWriter()) .stream(barWriter()) .build(); } @Bean public CustomCompositeItemWriter compositeItemWriter() { CustomCompositeItemWriter writer = new CustomCompositeItemWriter(); writer.setDelegate(barWriter()); return writer; } @Bean public BarWriter barWriter() { return new BarWriter(); }
1.6. Flat Files
バルクデータ連携の最も一般的な方式の一つはフラットファイルです。その構造(XSD)定義に対する合意に基づくXMLとは異なり、フラットファイルを読む側は前もってその構造を把握しておく必要があります。通常、フラットファイルは以下2つのどちらかのタイプ、デリミタか固定長、になります。デリミタファイルはデリミタ、カンマなど、でフィールドを区切ります。固定長ファイルはフィールド長が決まっています。
1.6.1. The FieldSet
Spring Batchでフラットファイルを処理する場合、入力・出力を問わず、最も重要なクラスの一つがFieldSetです。世の中多数のアーキテクチャとライブラリがファイル読み込み機能を提供しますが、これらは通常Stringかその配列を返します。これはやりたい事の半分でしかありません。FieldSetはファイルリソースとフィールドのバインディングを行うためのSpring Batchの機能です。これにより、DB入力と同じ方法でファイル入力も扱えます。FieldSetはコンセプト的にはJDBCのResultSetと似ています。FieldSetは単一の引数、String配列のトークン、を取ります。オプションで、フィールド名も設定可能で、このフィールドはインデックスか名前のどちらかでアクセスします。
String[] tokens = new String[]{"foo", "1", "true"}; FieldSet fs = new DefaultFieldSet(tokens); String name = fs.readString(0); int value = fs.readInt(1); boolean booleanValue = fs.readBoolean(2);
FieldSetには、Date, BigDecimalなどのオプションが多数存在します。FieldSetの最大の利点はフラットファイル入力のパースに一貫性を持たせられる点です。バッチジョブのパースをそれぞれ好き勝手に異なる方法でするより、フォーマット例外のハンドリングや、シンプルなデータ変換において、一貫性を持たせられます。
1.6.2. FlatFileItemReader
フラットファイルはおおむね2次元(表形式)データを持ちます。Spring Batchフレームワークでのフラットファイル読み込みはFlatFileItemReaderを呼ぶクラスで設定します。FlatFileItemReaderはフラットファイルの読み込みとパースの基本的な機能を提要します。FlatFileItemReaderの2つの重要な依存性はResourceとLineMapperです。LineMapperは次のセクションで解説します。resourceプロパティはSpring CoreのResourceです。この型のbeanの生成方法のドキュメントはSpring Framework, Chapter 5. Resourcesにあります。よって、このガイドではResourceオブジェクトの生成については以下のシンプルな例に留めます。
Resource resource = new FileSystemResource("resources/trades.csv");
複雑なバッチ環境では、ディレクトリ構造はEAIインフラで管理する事が多く、ここでは、外部インターフェース向けのdrop zoneはFTPアップロード先からバッチ処理用ディレクトリまたはその逆へのファイル移動で確立します。ファイル移動ユーティリティはSpring Batchのスコープ外ですが、ジョブストリームのステップにファイル移動ユーティリティを使う事はよくあります。バッチアーキテクチャは処理対象のファイルの場所だけは知っている必要があります。Spring Batchは開始ポイントからパイプへのデータフィード処理を開始します。なお、Spring Integrationはこの種のサービスを多数提供します。
FlatFileItemReaderのその他のプロパティには、以下表のような、データ処理方法の指定が可能です。
Table 1. FlatFileItemReader Properties
| Property | Type | Description |
|---|---|---|
| comments | String[] | コメント行を示すline prefixesを指定 |
| encoding | String | テキストエンコーディングを指定。デフォルトはCharset.defaultCharset() |
| lineMapper | LineMapper | StringからアイテムのObjectに変換 |
| linesToSkip | int | ファイル先頭から無視する行数 |
| recordSeparatorPolicy | RecordSeparatorPolicy | 行端識別に使用し、クオートで囲む1レコードを複数行にまたがらせたい場合などに使用 |
| resource | Resource | 読込対象リソース |
| skippedLinesCallback | LineCallbackHandler | スキップファイル行を受けるインタフェース。linesToSkipが2の場合このインタフェースは2回呼ばれる。 |
| strict | boolean | strictモードでは入力リソースが存在しない場合readerはExecutionContextに 例外をスローする。そうでない場合、ログ出力して処理継続する。 |
LineMapper
RowMapperがResultSetなどの低レベル要素を受け取りObjectを返すのと同様、フラットファイルの処理ではStringの行をObjectに変換します。
public interface LineMapper<T> { T mapLine(String line, int lineNumber) throws Exception; }
基本要素として、現在行とその行番号があり、このmapperはドメインオブジェクトを返します。RowMapper同様、行番号とそれに関連付けられたResultSetの各行のように、行番号と各行を持ちます。一意確認用にドメインジェクトと行番号を関連付けたり、ログに行番号を含めたりが出来ます。ただし、RowMapperと異なり、LineMapperには生データの行が渡されるので、前述のように、これだけでは不十分です。本ドキュメント後半で解説するように、オブジェクトにマッピング可能なFieldSetに行をトークンで分割してください。
LineTokenizer
入力行をFieldSet````に変換するインタフェースが必要です。FieldSetに変換したフラットファイルデータのフォーマットは多数考えられるためです。Spring Batchでは、それ用のインタフェースがLineTokenizer```です。
public interface LineTokenizer { FieldSet tokenize(String line); }
LineTokenizerの役割は、入力行(理論上Stringには複数行含める事も可能)を与えると、その行に対するFieldSetを返します。FieldSetはFieldSetMapperに渡します。Spring Batchは以下のLineTokenizer実装を提供します。
DelimitedLineTokenizer: レコードのフィールドがデリミタで区切られているファイルで使用する。最も一般的なのはカンマで、pipeやセミコロンもよく使います。FixedLengthTokenizer: レコードのフィールドが固定長のファイルで使用する。各フィールド長は個々のレコードタイプごとに定義する。PatternMatchingCompositeLineTokenizer: 行がパターンにマッチすると対応するLineTokenizerを使用する。
FieldSetMapper
FieldSetMapperには単一メソッドmapFieldSetがあり、FieldSetを取りオブジェクトにマッピングします。このオブジェクトは、job仕様に応じて、DTO・ドメインオブジェクト・配列などになります。FieldSetMapperはLineTokenizerと組み合わせて、リソースから適当な型にデータ行を変換するために使います。インタフェース定義は以下の通りです。
public interface FieldSetMapper<T> { T mapFieldSet(FieldSet fieldSet) throws BindException; }
JdbcTemplateのRowMapperと同じようなパターンになっています。
DefaultLineMapper
これまでの解説でフラットファイル読み込みのための基本的なインターフェース定義を見てきました。3つの基本的なステップが明確になりました。
- ファイルから1行読み込む。
StringをLineTokenizer#tokenize()に渡してFieldSetを取得する。- トークン処理が返す
FieldSetをFieldSetMapperに渡し、ItemReader#read()が結果を返す。
上述の2つのインタフェースが2つのタスク、FieldSet変換とFieldSetからドメインオブジェクトへのマッピング、を分離しています。LineTokenizerの入力はLineMapper(行)の入力と対応関係にあり、FieldSetMapperの出力はLineMapperの出力と対応関係があるので、LineTokenizerとFieldSetMapperの両方を使うデフォルト実装を用意しています。DefaultLineMapperは、以下のようなクラス定義で、大抵はこの振る舞いで十分です。
public class DefaultLineMapper<T> implements LineMapper<>, InitializingBean { private LineTokenizer tokenizer; private FieldSetMapper<T> fieldSetMapper; public T mapLine(String line, int lineNumber) throws Exception { return fieldSetMapper.mapFieldSet(tokenizer.tokenize(line)); } public void setLineTokenizer(LineTokenizer tokenizer) { this.tokenizer = tokenizer; } public void setFieldSetMapper(FieldSetMapper<T> fieldSetMapper) { this.fieldSetMapper = fieldSetMapper; } }
上述のデフォルト実装の機能は、(以前のバージョンのように)reader自体に組み込むのではなく、行を直接処理する場合のパース処理に高い柔軟性をユーザに提供しています。
Simple Delimited File Reading Example
以下は実際のシナリオに沿ってフラットファイルを読み込む方法の例の解説です。このバッチジョブは以下のファイルからフットボールプレイヤーを読み込みます。
ID,lastName,firstName,position,birthYear,debutYear "AbduKa00,Abdul-Jabbar,Karim,rb,1974,1996", "AbduRa00,Abdullah,Rabih,rb,1975,1999", "AberWa00,Abercrombie,Walter,rb,1959,1982", "AbraDa00,Abramowicz,Danny,wr,1945,1967", "AdamBo00,Adams,Bob,te,1946,1969", "AdamCh00,Adams,Charlie,wr,1979,2003"
ファイルの中身は以下のPlayerドメインオブジェクトにマッピングします。
public class Player implements Serializable { private String ID; private String lastName; private String firstName; private String position; private int birthYear; private int debutYear; public String toString() { return "PLAYER:ID=" + ID + ",Last Name=" + lastName + ",First Name=" + firstName + ",Position=" + position + ",Birth Year=" + birthYear + ",DebutYear=" + debutYear; } // setters and getters... }
FieldSetをPlayerにマッピングするには、以下のように、プレイヤーを返すFieldSetMapperを定義します。
protected static class PlayerFieldSetMapper implements FieldSetMapper<Player> { public Player mapFieldSet(FieldSet fieldSet) { Player player = new Player(); player.setID(fieldSet.readString(0)); player.setLastName(fieldSet.readString(1)); player.setFirstName(fieldSet.readString(2)); player.setPosition(fieldSet.readString(3)); player.setBirthYear(fieldSet.readInt(4)); player.setDebutYear(fieldSet.readInt(5)); return player; } }
次に、FlatFileItemReaderを正しく設定してreadを呼ぶことで、ファイルを読み込みます。
FlatFileItemReader<Player> itemReader = new FlatFileItemReader<Player>(); itemReader.setResource(new FileSystemResource("resources/players.csv")); //DelimitedLineTokenizer defaults to comma as its delimiter DefaultLineMapper<Player> lineMapper = new DefaultLineMapper<Player>(); lineMapper.setLineTokenizer(new DelimitedLineTokenizer()); lineMapper.setFieldSetMapper(new PlayerFieldSetMapper()); itemReader.setLineMapper(lineMapper); itemReader.open(new ExecutionContext()); Player player = itemReader.read();
readはファイルの各行を基にPlayerオブジェクトを返します。EOFに達するとnullを返します。
Mapping Fields by Name
DelimitedLineTokenizerとFixedLengthTokenizerの双方で使用可能な機能があり、JDBCのResultSetと似たような機能を持ちます。フィールド名をLineTokenizerに設定してマッピング関数の可読性を上げられます。まず、フラットファイルの全フィールドのカラム名をtokenizerに設定します。以下がその例です。
tokenizer.setNames(new String[] {"ID", "lastName","firstName","position","birthYear","debutYear"});
FieldSetMapperは以下のように上記のカラム名を使います。
public class PlayerMapper implements FieldSetMapper<Player> { public Player mapFieldSet(FieldSet fs) { if(fs == null){ return null; } Player player = new Player(); player.setID(fs.readString("ID")); player.setLastName(fs.readString("lastName")); player.setFirstName(fs.readString("firstName")); player.setPosition(fs.readString("position")); player.setDebutYear(fs.readInt("debutYear")); player.setBirthYear(fs.readInt("birthYear")); return player; } }
Automapping FieldSets to Domain Objects
多くの場合、FieldSetMapperを書くことはJdbcTemplateのRowMapper書くことと同じくらいに面倒です。名前とマッチするフィールドに、JavaBeanのsetterを用いて、自動マッピングするFieldSetMapperをSpring Batchは提供しています。再度フットボールの例にとると、BeanWrapperFieldSetMapperは以下のようになります。
Java Configuration
@Bean public FieldSetMapper fieldSetMapper() { BeanWrapperFieldSetMapper fieldSetMapper = new BeanWrapperFieldSetMapper(); fieldSetMapper.setPrototypeBeanName("player"); return fieldSetMapper; } @Bean @Scope("prototype") public Player player() { return new Player(); }
FieldSetの各エントリに対し、マッパーはPlayer新規インスタンス(このためprototypeスコープが飛鳥。)の対応するsetterを参照します。これはSpringコンテナがプロパティ名にマッチするsetterを参照するのと同様です。FieldSetの使用可能なフィールドをマッピングし、Playerオブジェクトを返します。上記設定以外のコードは不要です。
Fixed Length File Formats
これまではデリミタファイルの詳細のみ解説してきました。しかし、それだけでは片手落ちです。固定長フォーマットのフラットファイルを使用する組織は数多く存在します。固定長の例は以下の通りです。
UK21341EAH4121131.11customer1 UK21341EAH4221232.11customer2 UK21341EAH4321333.11customer3 UK21341EAH4421434.11customer4 UK21341EAH4521535.11customer5
1つの大きなフィールドに見えますが、実際には4つの独立したフィールドです。
- ISIN: 注文商品の一意識別子 - 12文字
- Quantity: 個数 - 3文字
- Price: 価格 - 5文字
- Customer: 顧客ID - 9文字
FixedLengthLineTokenizerを設定する場合、以下例のように、長さをレンジ形式で指定する必要があります。
※ レンジ形式は専用のproperty editorのRangeArrayPropertyEditorをApplicationContextに入れる必要があります。ただし、このbeanはbatch namespaceを使う場合はApplicationContextに自動設定されます。
Java Configuration
@Bean public FixedLengthTokenizer fixedLengthTokenizer() { FixedLengthTokenizer tokenizer = new FixedLengthTokenizer(); tokenizer.setNames("ISIN", "Quantity", "Price", "Customer"); tokenizer.setColumns(new Range(1-12), new Range(13-15), new Range(16-20), new Range(21-29)); return tokenizer; }
FixedLengthLineTokenizerはこれまでに説明してきたLineTokenizerの一種なので、デリミタの場合と同様にFieldSetを返します。その出力処理についても同様で、BeanWrapperFieldSetMapperなどが使えます。
Multiple Record Types within a Single File
これまでのファイル読み込みサンプルは説明簡略化のため、ファイルの全レコードが同一フォーマットである、という仮定を置いていました。しかし、そうでない場合もあります。各レコードの異なるフォーマットに異なるトークン処理をして異なるオブジェクトにマッピングするファイルもありえます。以下はそうしたファイルの抜粋です。
USER;Smith;Peter;;T;20014539;F LINEA;1044391041ABC037.49G201XX1383.12H LINEB;2134776319DEF422.99M005LI
このファイルには3種類のレコード、USER", "LINEA", and "LINEB"、があります。"USER"はUserに相当し、"LINEA"と"LINEB"は共にLineに相当し、"LINEA"は"LINEB"よりも多くのデータを持ちます。
ItemReaderは個々の行を独立に読みますが、ItemWriterが正しくアイテムを受け取れるように、各行に対して異なるLineTokenizerとFieldSetMapperを指定する必要があります。PatternMatchingCompositeLineMapperは、パターンとLineTokenizerのマッピングおよびパターンとFieldSetMapperのマッピング、を指定することで、これを簡単に設定できます。
Java Configuration
@Bean public PatternMatchingCompositeLineMapper orderFileLineMapper() { PatternMatchingCompositeLineMapper lineMapper = new PatternMatchingCompositeLineMapper(); Map<String, LineTokenizer> tokenizers = new HashMap<>(3); tokenizers.put("USER*", userTokenizer()); tokenizers.put("LINEA*", lineATokenizer()); tokenizers.put("LINEB*", lineBTokenizer()); lineMapper.setTokenizers(tokenizers); Map<String, FieldSetMapper> mappers = new HashMap<>(2); mappers.put("USER*", userFieldSetMapper()); mappers.put("LINE*", lineFieldSetMapper()); lineMapper.setFieldSetMappers(mappers); return lineMapper; }
この例では、"LINEA"と"LINEB" はそれぞれ別のLineTokenizerですが、FieldSetMapperは同じものを使います。
PatternMatchingCompositeLineMapperはPatternMatcher#matchで各行に対する委譲先の選択を行います。PatternMatcherには2つのワイルドカード特殊文字が使えます。クエスチョンマーク("?")は1文字のみにマッチし、アスタリスク("")はゼロ文字以上にマッチします。上の設定例では、すべてのパターンの最後にアスタリスクを付与しており、各行のプレフィックスとマッチするようにしています。PatternMatcherは、設定順序に関わらず、常に可能な限り最も一致するパターンにマッチします(matches the most specific pattern possible)。このため、"LINE"と"LINEA"がパターンリストにある場合、"LINEA"はパターン"LINEA"にマッチし、"LINEB"はパターン"LINE"にマッチします。なお、アスタリスクのみ("")はデフォルトとして振る舞い、他パターンがマッチしないすべての行にマッチします。
Java Configuration
... tokenizers.put("*", defaultLineTokenizer()); ...
また、トークン処理にPatternMatchingCompositeLineTokenizerを単独で使う事も可能です。
複数行にまたがるレコードを持つフラットファイルもあります。これの対処には、さらに複雑な方法が必要となります。このための一般的なパターンの解説はmultiLineRecordsのサンプルコードにあります。
Exception Handling in Flat Files
トークン処理が例外をスローするケースは多数考えられます。フラットファイルが不完全で不正確なフォーマットのレコードを持つ場合があります。大抵の場合は、ログに問題・オリジナルの行・行番後を出力し、エラー行をスキップします。ログは後々に別のバッチジョブや手動調査に使います。このため、Spring Batchはパース例外処理、FlatFileParseExceptionとFlatFileFormatException、の例外の階層を持っています。ファイル読み込み時に何らかのエラーが発生する場合、FlatFileItemReaderはFlatFileParseExceptionをスローします。LineTokenizer実装はトークン処理中に発生したエラーを示すFlatFileFormatExceptionをスローします。
IncorrectTokenCountException
DelimitedLineTokenizerとFixedLengthLineTokenizerはFieldSetの生成にカラム名を指定します。しかし、カラム名の個数がトークン処理時にマッチしない場合、FieldSetは生成できず、トークンの個数と期待値を持つIncorrectTokenCountExceptionをスローします。
tokenizer.setNames(new String[] {"A", "B", "C", "D"}); try { tokenizer.tokenize("a,b,c"); } catch(IncorrectTokenCountException e){ assertEquals(4, e.getExpectedCount()); assertEquals(3, e.getActualCount()); }
tokenizerには4つのカラム名を設定していますが、ファイルからは3トークンしか検出出来ないと、IncorrectTokenCountExceptionをスローします。
IncorrectLineLengthException
固定長フォーマットの場合、デリミタとは異なり、パース時に各カラムが厳密に定義した長さに従う必要があります。行の長さが異なる場合、例外をスローします。
tokenizer.setColumns(new Range[] { new Range(1, 5), new Range(6, 10), new Range(11, 15) }); try { tokenizer.tokenize("12345"); fail("Expected IncorrectLineLengthException"); } catch (IncorrectLineLengthException ex) { assertEquals(15, ex.getExpectedLength()); assertEquals(5, ex.getActualLength()); }
上記のtokenizerの設定範囲は1-5, 6-10, and 11-15です。よって、行の合計の長さは15です。しかし、上の例では、長さ5の行が渡され、IncorrectLineLengthExceptionをスローします。最初のカラムのみマッピングするよりも、例外スローによって行処理を早めに失敗させる事が可能となり、FieldSetMapperで2カラム目を読み込む際にエラーにするよりも多くの情報を返せます。しかし、行の長さが常に一定ではないケースも存在します。このため、行の長さのvalidationは'strict'プロパティによりオフにできます。
tokenizer.setColumns(new Range[] { new Range(1, 5), new Range(6, 10) }); tokenizer.setStrict(false); FieldSet tokens = tokenizer.tokenize("12345"); assertEquals("12345", tokens.readString(0)); assertEquals("", tokens.readString(1));
上の例は、okenizer.setStrict(false)以外、一つ前の例とおおむね同一です。この設定により、tokenizerで行のトークン処理時に長さチェックをしなくなります。これでFieldSetは正しく生成されて返されます。なお、残りの値については空のトークンになります。
1.6.3. FlatFileItemWriter
フラットファイル書き込みには読み込みと同じ解決すべき問題と課題があります。transactionalにデリミタあるいは固定長フォーマットで書き込み可能なstepにする必要があります。
LineAggregator
LineTokenizer同様、アイテムをStringに変換する必要があり、ファイルへ書き込むために複数フィールドを単一の文字列へ集約する必要があります。Spring Batchでは、これはLineAggregatorが担います。インタフェース定義は以下の通りです。
public interface LineAggregator<T> { public String aggregate(T item); }
LineAggregatorとLineTokenizerは論理的な対応関係にあります。LineTokenizerはStringをFieldSetにし、一方、LineAggregatorはitemをStringにします。
PassThroughLineAggregator
LineAggregatorの一番簡単な実装はPassThroughLineAggregatorで、オブジェクトがすでに文字列であるか、オブジェクトの文字列表現を書き込んでも問題無い、と想定できる場合に使います。
public class PassThroughLineAggregator<T> implements LineAggregator<T> { public String aggregate(T item) { return item.toString(); } }
上の実装は、文字列生成を直接制御する必要はあるものの、FlatFileItemWriterの利点であるトランザクションやリスタート機能などは必要な場合に便利です。
Simplified File Writing Example
LineAggregatorインタフェースとその一番簡単な実装のPassThroughLineAggregatorを見たので書き込みの基本的なフローを解説します。
- 書き込むオブジェクトを
LineAggregatorに渡してStringを得る。 - 返された
Stringが設定したファイルに書き込まれる。
以下のFlatFileItemWriterの抜粋がそのコード部分です。
public void write(T item) throws Exception { write(lineAggregator.aggregate(item) + LINE_SEPARATOR); }
簡単な設定例は以下の通りです。
Java Configuration
@Bean public FlatFileItemWriter itemWriter() { return new FlatFileItemWriterBuilder<Foo>() .name("itemWriter") .resource(new FileSystemResource("target/test-outputs/output.txt")) .lineAggregator(new PassThroughLineAggregator<>()) .build(); }
FieldExtractor
上の例はファイル書き込みの一番簡単な使用法として有用です。しかし、FlatFileItemWriterのユーザは基本的にはドメインオブジェクトを書き込む必要があるため、これを行に変換する必要があります。ファイル読み込みでは、以下が必要でした。
- ファイルから1行読み込む。
- その行を
LineTokenizer#tokenize()に渡してFieldSetを得る。 - トークン処理結果の
FieldSetをFieldSetMapperに渡し、ItemReader#read()が結果を返す。
ファイル書き込みも似た構造になりますが手順は逆になります。
- writerに書き込むアイテムを渡す。
- アイテムのフィールドを配列に変換。
- 配列を行に集約する。
フレームワークは書き込みたいオブジェクトのフィールドを知らないので、アイテムを配列に変換するタスク用のFieldExtractorを指定する必要があります。インタフェース定義は以下になります。
public interface FieldExtractor<T> { Object[] extract(T item); }
FieldExtractorの実装はオブジェクトのフィールドから配列を生成し、デリミタ区切りの要素や固定長の行の一部にこの配列を使用します。
PassThroughFieldExtractor
配列・Collection・FieldSetなどコレクションを書き込む必要があるケースは多くあります。これらのコレクション型から配列を"抽出"するのは極めて単純で、コレクションから配列に変換します。よって、PassThroughFieldExtractorはそういう場合に使います。なお、非コレクション型のオブジェクトを渡す場合、PassThroughFieldExtractorはそのアイテムのみを含む配列を返します。
BeanWrapperFieldExtractor
前述の読み込みセクションのBeanWrapperFieldSetMapper同様、変換を自分で書くのではなく、ドメインオブジェクトを配列に変換したい場合に使います。BeanWrapperFieldExtractorのこの機能は以下の例のように使います。
BeanWrapperFieldExtractor<Name> extractor = new BeanWrapperFieldExtractor<Name>(); extractor.setNames(new String[] { "first", "last", "born" }); String first = "Alan"; String last = "Turing"; int born = 1912; Name n = new Name(first, last, born); Object[] values = extractor.extract(n); assertEquals(first, values[0]); assertEquals(last, values[1]); assertEquals(born, values[2]);
extractor実装には必須プロパティが1つだけあり、マッピング用に使うフィールド名を渡しますBeanWrapperFieldSetMapperはオブジェクトのsetterにFieldSetをマッピングするのにフィールド名を使います。BeanWrapperFieldExtractorはオブジェクト配列を生成するためにgetterとフィールド名の配列とをマッピングします。フィールド名配列の順序が配列内のフィールドの順序となる点に注意してください。
Delimited File Writing Example
一番簡単なフラットファイルフォーマットはすべてのフィールドがデリミタで区切ったものです。この場合はDelimitedLineAggregatorを使います。以下の例はクレジットと顧客アカウントを表すシンプルなオブジェクトを出力する例です。
public class CustomerCredit { private int id; private String name; private BigDecimal credit; //説明簡略化のためgetters,settersは省略 }
ドメインオブジェクトを使うため、FieldExtractor実装をデリミタ指定で必要があります。
Java Configuration
@Bean public FlatFileItemWriter<CustomerCredit> itemWriter(Resource outputResource) throws Exception { BeanWrapperFieldExtractor<CustomerCredit> fieldExtractor = new BeanWrapperFieldExtractor<>(); fieldExtractor.setNames(new String[] {"name", "credit"}); fieldExtractor.afterPropertiesSet(); DelimitedLineAggregator<CustomerCredit> lineAggregator = new DelimitedLineAggregator<>(); lineAggregator.setDelimiter(","); lineAggregator.setFieldExtractor(fieldExtractor); return new FlatFileItemWriterBuilder<CustomerCredit>() .name("customerCreditWriter") .resource(outputResource) .lineAggregator(lineAggregator) .build(); }
上の例では、このチャプター前半で解説したBeanWrapperFieldExtractorでCustomerCreditのnameとcreditフィールドを配列に変換し、各フィールドをカンマで書き込みます。
なお、以下例のように、FlatFileItemWriterBuilder.DelimitedBuilderでBeanWrapperFieldExtractorとDelimitedLineAggregatorを内部的に自動生成する使い方も可能です。
Java Configuration
@Bean public FlatFileItemWriter<CustomerCredit> itemWriter(Resource outputResource) throws Exception { return new FlatFileItemWriterBuilder<CustomerCredit>() .name("customerCreditWriter") .resource(outputResource) .delimited() .delimiter("|") .names(new String[] {"name", "credit"}) .build(); }
Fixed Width File Writing Example
デリミタがフラットファイルの唯一のフォーマットではありません。固定長という、フィールドの区切りに各カラムが長さを持つ場合もあります。Spring BatchはFormatterLineAggregatorで固定長を扱います。上の説明で使用したCustomerCreditの場合、以下のように使います。
Java Configuration
@Bean public FlatFileItemWriter<CustomerCredit> itemWriter(Resource outputResource) throws Exception { BeanWrapperFieldExtractor<CustomerCredit> fieldExtractor = new BeanWrapperFieldExtractor<>(); fieldExtractor.setNames(new String[] {"name", "credit"}); fieldExtractor.afterPropertiesSet(); FormatterLineAggregator<CustomerCredit> lineAggregator = new FormatterLineAggregator<>(); lineAggregator.setFormat("%-9s%-2.0f"); lineAggregator.setFieldExtractor(fieldExtractor); return new FlatFileItemWriterBuilder<CustomerCredit>() .name("customerCreditWriter") .resource(outputResource) .lineAggregator(lineAggregator) .build(); }
今までに見てきた例とほぼ同じですが、formatプロパティ値はここで初めて登場します。
... FormatterLineAggregator<CustomerCredit> lineAggregator = new FormatterLineAggregator<>(); lineAggregator.setFormat("%-9s%-2.0f"); ...
これの内部実装はJava 5で導入されたFormatterをベースにしています。JavaのFormatterはC言語のprintfをベースにしています。formatter設定の詳細についてはFormatterを参照してください。
なお、以下例のように、FlatFileItemWriterBuilder.FormattedBuilderでBeanWrapperFieldExtractorとFormatterLineAggregatorを内部的に自動生成する使い方も可能です。
Java Configuration
@Bean public FlatFileItemWriter<CustomerCredit> itemWriter(Resource outputResource) throws Exception { return new FlatFileItemWriterBuilder<CustomerCredit>() .name("customerCreditWriter") .resource(outputResource) .formatted() .format("%-9s%-2.0f") .names(new String[] {"name", "credit"}) .build(); }
Handling File Creation
FlatFileItemReaderとファイルリソースとの関係は極めてシンプルです。readerを初期化すると、(存在する)ファイルをオープンし、無ければ例外をスローします。ファイル書き込みはこのようにシンプルではありません。一見、FlatFileItemWriterにも同様なシンプルな関係があるように思えます。ファイルがあれば例外をスローし、無ければ生成して書き込みを開始する。ただし、Jobリスタートがあり得る場合は問題を起こす可能性があります。通常のリスタートでは、ファイルが存在する場合、最終ポジションから書き込みを開始し、存在しなければ例外をスローします。しかし、このjobのファイル名が常に同一の場合どうなるでしょうか? この場合、リスタートで無ければ、存在するファイルを削除したいと考えるはずです。こういった課題があるため、FlatFileItemWriterにはshouldDeleteIfExistsプロパティがあります。このプロパティをtrueにするとwriterオープン時に同一名のファイルが存在すれば削除します。