https://docs.spring.io/spring-batch/4.1.x/reference/html/domain.html#domainLanguageOfBatch
https://qiita.com/kagamihoge/items/12fbbc2eac5b8a5ac1e0 俺の訳一覧リスト
1. The Domain Language of Batch
何らかの経験のあるバッチアーキテクトにとって、Spring Batchのバッチ処理のコンセプトはお馴染みのものです。"Jobs"、"Steps"、開発者が用意する処理単位のItemReaderとItemWriterがあります。ただ、Springのパターン, operations, テンプレート、コールバック、イディオムを使えるので、以下も可能です。
- 関心事の分離による品質向上。
- インターフェースによるサービスとレイヤーの明確化。
- シンプルなデフォルト実装により、そのままの設定ですぐ動かせる。
- 拡張性の大幅な機能強化。
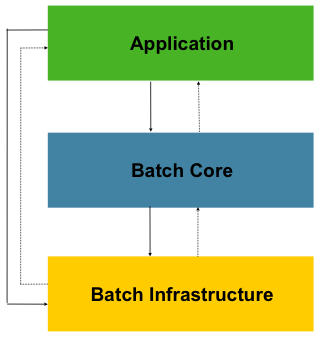
以下の図はここ数十年使われ続けてきたバッチのリファレンスアーキテクチャを単純化したものです。バッチ処理のドメイン言語を構成するコンポーネントの概略を示しています。このアーキテクチャフレームワークの設計はここ数世代の複数プラットフォーム(COBOL/Mainframe, C/Unix, and now Java/anywhere)の実装を通して実証されてきました。JCLとCOBOLの開発者は、C, C#, Java開発者と同様に、このコンセプトに慣れていると思われます。Spring Batchは、広範なバッチアプリケーション開発に使われるメンテナンス性がありロバストなシステムで、広く見られるサービス・コンポーネント・レイヤの実装を提供します。また、非常に複雑な要求を扱うための拡張とインフラも備えています。
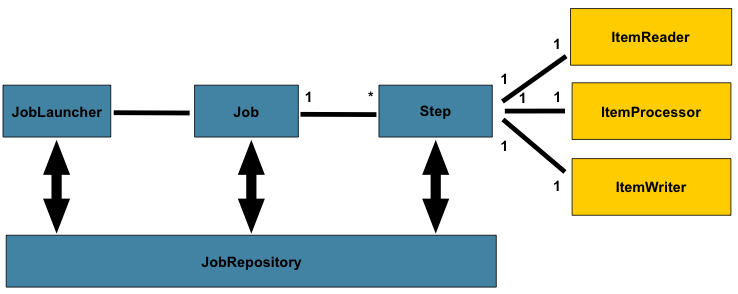
Figure 1. Batch Stereotypes
上図はSpring Batchのドメイン言語を構成する中核コンセプトを表しています。Jobは一つか複数のstepを持ち、各stepはItemReader, ItemProcessor, ItemWriterを一つ持ちます。jobは(JobLauncher)で実行し、現在実行中のプロセスのメタデータは(JobRepository)に保存されます。
1.1. Job
このセクションではbatch jobのコンセプトに関する解説をします。Jobはバッチ処理全体をカプセル化するエンティティです。他のSpringプロジェクト同様に、JobはXMLかJavaのどちらかの設定でワイヤリングします。この設定は"job configuration"と呼ばれる事が多いです。なお、以下の図で示すように、Jobは階層全体のトップに居ます。
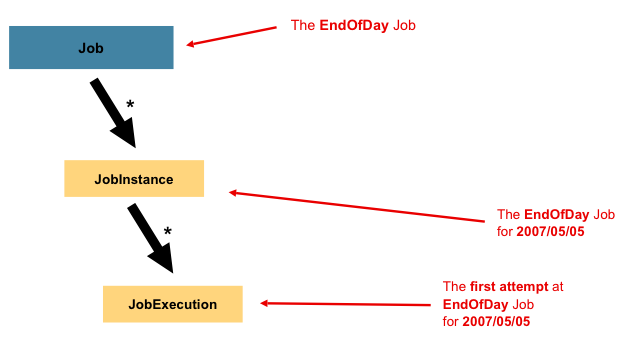
Figure 2. Job Hierarchy
Spring Batchでは、JobはStepインスタンスのコンテナです。jobは複数のstepを持ち、これらはフロー内の論理的なまとまりを構成し、リスタートなど全てのstepにグローバルなプロパティ設定があります。job設定は以下があります。
- job名。
Stepインスタンスの定義と順序。- jobがリスタート可能かどうか。
Spring BatchのデフォルトJob実装はSimpleJobクラスで、Jobにいくつかの標準機能を追加しています。Java設定の場合、Jobのインスタンス化に利用可能なビルダーが複数あり、以下はその例です。
@Bean public Job footballJob() { return this.jobBuilderFactory.get("footballJob") .start(playerLoad()) .next(gameLoad()) .next(playerSummarization()) .end() .build(); }
1.1.1. JobInstance
JobInstanceはjob実行に相当します。いま、一日の終わりに一度だけ実行する、前述の図の'EndOfDay' Job、などのバッチjobを考えます。jobは'EndOfDay'の1つですが、Jobの個々の実行はそれぞれ別個に扱う必要があります。このjobの場合、1日1つのJobInstanceになります。例えば、1/1の実行、1/2の実行、になりま1す。1/1の実行が初回は失敗したが翌日再実行する場合、1/1の実行を再度走らせます(通常、バッチ実行は処理するデータと対応関係があるので、1/1の実行は1/1のデータを処理します)。よって、JobInstanceは複数の実行を持ちうる(JobExecutionはこの賞の後半で解説します)事になり、特定のJobに対応するJobInstanceは一つだけで、JobParametersである特定時点のJobInstanceを実行します。
JobInstance定義はロードされるデータとは完全に無関係です。データのロード方法はItemReaderの実装次第です。たとえば、EndOfDayのケースだと、 'effective date'や'schedule date'を指すデータ列が考えらます。よって、1/1の実行は1/1のデータのみロードし、1/2は1/2のデータのみロードします。これは仕様次第で、ItemReaderで実装します。ただし、同一JobInstanceを使用すると、以前の実行の'state'(ExecutionContextの事でこの章の後半で解説)かどうかが決まります。新規のJobInstanceは'最初から開始'を意味し、既存インスタンスは基本的には'抜けた場所から開始'を意味します。
1.1.2. JobParameters
JobInstanceとそのJobとの違いを解説したので、"JobInstanceの区別方法は?"という疑問が自然に浮かぶと思われます。答えはJobParametersです。JobParametersオブジェクトはバッチjobに使うパラメータを保持します。識別に使われる他、以下の図のように、実行中の参照データとしても使われます。
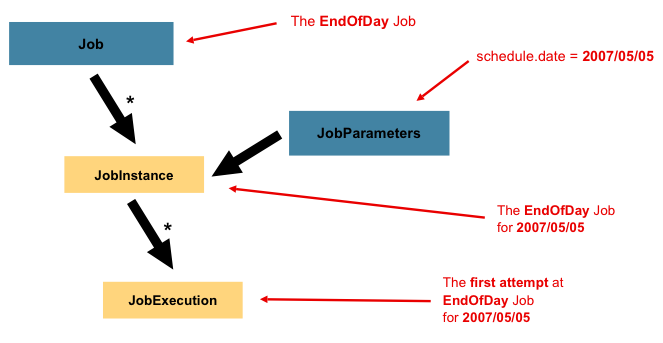
Figure 3. Job Parameters
先の例では、二つのインスタンスがあり、一つは1/1でもう一つが1/2、Job1つだけですが、JobParameterオブジェクトは2つあります。前者はパラメータ01-01-2017で開始しており、後者は01-02-2017で開始しています。よって、定義としてはJobInstance = Job + JobParametersになります。これにより、開発者はJobInstanceの定義を、渡すパラメータによって、制御します。
※ JobInstanceの識別にすべてのjobパラメータが必要なわけではありません。By default, they do so. ただし、このフレームワークでは、JobInstanceの識別に使用しないパラメータでJobのサブミットが可能です。
1.1.3. JobExecution
JobExecutionは1回のjob実行に相当します。実行は失敗か成功で終了しますが、ある実行が正常終了しない限り、対応するJobInstanceは完了したとは見なされません。例としてEndOfDayのJobで解説すると、01-01-2017のJobInstanceが初回実行時に失敗した場合を考えます。初回実行(01-01-2017)と同一のjob parametersで再度実行すると、JobExecutionを新規に作成します。ただし、JobInstanceは1つのままです。
Jobはjobの中身と実行方法を定義し、JobInstanceは実行をグループ化するオブジェクトで、これは主に正しくリスタートするためです。一方で、JobExecutionは、実行中に発生した事を格納する役割があり、制御と永続化されるプロパティがあります。
Table 1. JobExecution Properties
| Property | Definition |
|---|---|
| Status | 実行ステータスを示すBatchStatus。実行時、BatchStatus#STARTED。失敗、BatchStatus#FAILED。正常終了、BatchStatus#COMPLETED |
| startTime | 実行開始時の現在システム時刻のjava.util.Date 。jobがまだ開始していない場合は空。 |
| endTime | 実行終了時の現在システム時刻のjava.util.Date。成功かどうかは無関係。jobがまだ終了していない場合は空。 |
| exitStatus | 実行結果を示すExitStatus。呼び出し元に返される終了コードなので、最も重要。詳細は5章参照。jobがまだ終了していない場合は空。 |
| createTime | JobExecutionを最初に永続化した時点の現在システム時刻のjava.util.Date 。jobが未開始の場合がある(その場合startTimeも空)が、jobレベルのExecutionContextsを管理する上でフレームワークはcreateTimeを必要とします。 |
| lastUpdated | JobExecutionを最後の永続化した時間のjava.util.Date。jobが未開始の場合は空。 |
| executionContext | 複数のexecution間で永続化の必要があるユーザデータを持つ、プロパティの入れ物。 |
| failureExceptions | Job実行中に発生した例外リスト。Jobの失敗時に複数の例外が発生した場合に役立ちます。 |
これらプロパティは永続化され、実行ステータスの決定に使われる点が重要です。例えば、1/1のEndOfDay jobが9:00 PMに実行して9:30に失敗した場合、以下のエントリがメタデータテーブルに作られます。
Table 2. BATCH_JOB_INSTANCE
| JOB_INST_ID | JOB_NAME |
|---|---|
| 1 | EndOfDayJob |
Table 3. BATCH_JOB_EXECUTION_PARAMS
| JOB_EXECUTION_ID | TYPE_CD | KEY_NAME | DATE_VAL | IDENTIFYING |
|---|---|---|---|---|
| 1 | DATE | schedule.Date | 2017-01-01 | TRUE |
Table 4. BATCH_JOB_EXECUTION
| JOB_EXEC_ID | OB_INST_ID | START_TIME | END_TIME | STATUS |
|---|---|---|---|---|
| 1 | 1 | 2017-01-01 21:00 | 2017-01-01 21:30 | FAILED |
※カラム名は説明のために削除したり簡略化しているものがあります。
いま、jobが失敗し、問題解決には一晩かかるとし、バッチウィンドウ('batch window')は終了しています。次に、ウィンドウ開始を9:00 PM、1/1のjobを再度開始、前回失敗箇所から開始して9:30に正常終了しました。この時すでに翌日になっており、1/2のjobも走らせる必要があるので、その直後の9:31に開始して通常の1時間で10:30に完了しました。1つのJobInstanceを連続実行する事に特に要求事項は無いですが、2つのjobが同一データにアクセスする可能性が無い限りにおいてであり、これはDBレベルでロックを引き起こしかねないためです。いつJobを実行するかどうかはスケジューラーに完全に依存します。別々のJobInstancesなので、Spring Batchはコンカレントな実行を止めません。(同一のJobInstanceが実行中の場合、JobExecutionAlreadyRunningExceptionをスローします。)最終的に、以下表のように、JobInstanceとJobParametersテーブルに行が追加され、JobExecutionに2行追加されます。
Table 5. BATCH_JOB_INSTANCE
| JOB_INST_ID | JOB_NAME |
|---|---|
| 1 | EndOfDayJob |
| 2 | EndOfDayJob |
Table 6. BATCH_JOB_EXECUTION_PARAMS
| JOB_EXECUTION_ID | TYPE_CD | KEY_NAME | DATE_VAL | IDENTIFYING |
|---|---|---|---|---|
| 1 | DATE | schedule.Date | 2017-01-01 00:00:00 | TRUE |
| 2 | DATE | schedule.Date | 2017-01-01 00:00:00 | TRUE |
| 3 | DATE | schedule.Date | 2017-01-02 00:00:00 | TRUE |
Table 7. BATCH_JOB_EXECUTION
| JOB_EXEC_ID | JOB_INST_ID | START_TIME | END_TIME | STATUS |
|---|---|---|---|---|
| 1 | 1 | 2017-01-01 21:00 | 2017-01-01 21:30 | FAILED |
| 2 | 1 | 2017-01-02 21:00 | 2017-01-02 21:30 | COMPLETED |
| 3 | 2 | 2017-01-02 21:31 | 2017-01-02 22:29 | COMPLETED |
※カラム名は説明のために削除したり簡略化しているものがあります。
1.2. Step
Stepは、バッチjobのシーケンシャルで独立したフェーズ、をカプセル化したドメインオブジェクトです。よって、すべてのJobは必ず1つ以上のstepで構成します。Stepには実際のバッチ処理を定義したり制御するのに必要なすべての情報を持ちます。これは全く持って曖昧な説明ですが、Stepの中身は開発者が書くJob次第なためです。Stepは開発者次第でシンプルなものから複雑なものまで作成出来ます。シンプルなStepはファイルからDBにデータをロードし、コードは全く書かないか少量で済みます(実装依存)。複雑なStepは、何らかの処理の一部となる複雑なビジネスルールを持つものが考えられます。Job同様、Stepは複数のStepExecutionを持ち、1つのJobExecutionと関連を持ちます。以下がイメージ図です。
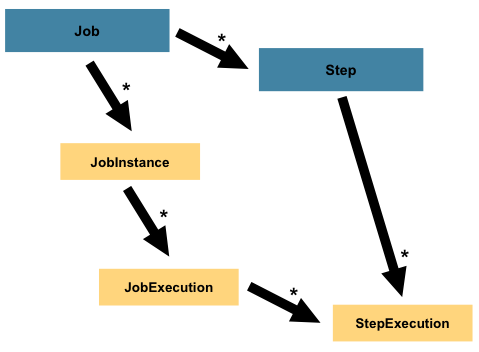
igure 4. Job Hierarchy With Steps
1.2.1. StepExecution
StepExecutionはStepの1回分の実行を表現したものです。JobExecution同様に、Stepが実行される度に新規にStepExecutionを生成します。もしstepが実行に失敗するとき、原因がそのstepより前にある場合、そのstepのexecutionは永続化しません。StepExecutionはStepが実際に開始した後にだけ生成します。
Stepの実行はStepExecutionクラスのオブジェクトで表現します。それぞれの実行は、対応するstep・JobExecution・トランザクション関連データ、このデータはコミット・ロールバックカウント・開始終了時刻など、を持ちます。また、それぞれのstep executionはExecutionContextを持ち、ここには開発者がバッチ実行中に永続化しておきたい任意のデータ、例えば統計やリスタートに必要な状態、を持たせます。以下はStepExecutionのプロパティリストです。
Table 8. StepExecution Properties
| Property | Definition |
|---|---|
| Status | 実行ステータスを示すBatchStatusオブジェクト。実行中BatchStatus.STARTED。失敗BatchStatus.FAILED。正常終了BatchStatus.COMPLETED。 |
| startTime | 実行開始時の現在システム時刻のjava.util.Date 。stepがまだ開始していない場合は空。 |
| endTime | 実行終了時の現在システム時刻のjava.util.Date。成功かどうかは無関係。stepがまだ終了していない場合は空。 |
| exitStatus | 実行結果を示すExitStatus。呼び出し元に返される終了コードなので、最も重要。詳細は5章参照。jobがまだ終了していない場合は空。 |
| executionContext | 複数のexecution間で永続化の必要があるユーザデータを持つ、プロパティの入れ物。 |
| readCount | 正常に読み込んだアイテム数。 |
| writeCount | 正常に書き込んだアイテム数。 |
| commitCount | この実行でコミットしたトランザクション数。 |
| rollbackCount | Stepで制御するビジネストランザクションのロールバック数。 |
| readSkipCount | readが失敗した回数。アイテムスキップとなる。 |
| processSkipCount | processが失敗した回数。アイテムスキップとなる。 |
| filterCount | ItemProcessorがフィルターしたアイテム数。 |
| writeSkipCount | writeが失敗した回数。アイテムスキップとなる。 |
1.3. ExecutionContext
ExecutionContextはフレームワークが制御および永続化するkey/valueのコレクションで、開発者が永続化状態を保存する場所です。これはStepExecutionもしくはJobExecutionスコープになります。Quartzで言うところのJobDataMapです。最も良く使われる例としてはリスタートの調整です。入力としてフラットファイルを取る例で言うと、個々の行を処理中、フレームワークは定期的にコミットポイントでExecutionContextを永続化します。これにより、ItemReaderで実行中に致命的エラーが発生してもその状態を保存します。これを実装するには、以下例のように、コンテキストに読み込んだ現在行をputすると、あとはフレームワークがやってくれます。
executionContext.putLong(getKey(LINES_READ_COUNT), reader.getPosition());
例としてJobセクションのEndOfDayサンプルの場合、'loadData'というファイルをDBにロードするstepが一つあるとします。最初の実行が失敗後、メタデータテーブルは以下の例になります。
Table 9. BATCH_JOB_INSTANCE
| JOB_INST_ID | JOB_NAME |
|---|---|
| 1 | EndOfDayJob |
Table 10. BATCH_JOB_EXECUTION_PARAMS
| JOB_INST_ID | TYPE_CD | KEY_NAME | DATE_VAL |
|---|---|---|---|
| 1 | DATE | schedule.Date | 2017-01-01 |
Table 11. BATCH_JOB_EXECUTION
| JOB_EXEC_ID | JOB_INST_ID | START_TIME | END_TIME | STATUS |
|---|---|---|---|---|
| 1 | 1 | 2017-01-01 21:00 | 2017-01-01 21:30 | FAILED |
Table 12. BATCH_STEP_EXECUTION
| STEP_EXEC_ID | JOB_EXEC_ID | STEP_NAME | START_TIME | END_TIME | STATUS |
|---|---|---|---|---|---|
| 1 | 1 | loadData | 2017-01-01 21:00 | 2017-01-01 21:30 | FAILED |
Table 13. BATCH_STEP_EXECUTION_CONTEXT
| STEP_EXEC_ID | SHORT_CONTEXT |
|---|---|
| 1 | {piece.count=40321} |
上の場合、Stepは30分実行し、このシナリオにおけるファイル行であるところの40,321 'pieces'を処理しています。この値はフレームワークがコミット直前に更新します。また、`この値にはExecutionContextの複数エントリに対応する形で複数行を含められます。コミット前に通知を受けるには何らかのStepListener実装(かItemStream)が必要で、詳細は本が意図の後半で扱います。前述の例同様、ここでもJobを翌日にリスタートする、とします。リスタートすると、最終実行時のExecutionContextの値をDBから再構成します。ItemReaderがopenすると、以下例のように、コンテキストに保存した状態があればチェックしてその値で初期化します。
if (executionContext.containsKey(getKey(LINES_READ_COUNT))) { log.debug("Initializing for restart. Restart data is: " + executionContext); long lineCount = executionContext.getLong(getKey(LINES_READ_COUNT)); LineReader reader = getReader(); Object record = ""; while (reader.getPosition() < lineCount && record != null) { record = readLine(); } }
この例の場合、上のコードを実行すると、カレントの行は40322になり、Stepは前回失敗箇所からの再実行が可能となります。また、ExecutionContextにはその実行に関して永続化したい統計情報にも使えます。例えば、フラットファイルが複数行に存在する処理命令(orders for processing)を含むケースでは、処理した命令数(読み込んだ行数とは異なる)を保存し、Stepの最後に合計処理命令数をメールで送るような処理が可能です。それぞれのJobInstanceで正確なスコープにするため、フレームワークがそれらの情報を保存します。すでに在るExecutionContextが使われるかどうかを知ることは困難です。たとえば、上記の 'EndOfDay' の例で言うと、1/1を2回目に実行するとき、フレームワークは同一JobInstanceとStepであると解釈し、DBからExecutionContextを取得し、その取得データを(StepExecutionの一部として)Stepに渡します。一方で、1/2実行時には、フレームワークは別のインスタンスであると解釈し、よって空のコンテキストをStepに渡します。There are many of these types of determinations that the framework makes for the developer, to ensure the state is given to them at the correct time. また、ある時点において1つのStepExecutionには1つのExecutionContextだけが存在する点は重要です。ExecutionContextを使う際には注意が必要で、このインスタンスは共有のキースペース(a shared keyspace)を生成するためです。このため、データを上書きしないような注意が必要です。ただし、Stepがコンテキストに何もデータを保存しないのであれば、フレームワークには何も影響を与えません。
1つのJobExecutionに少なくとも1つのExecutionContext、それぞれのStepExecutionごとに1つのExecutionContext、が存在する点も重要です。例えば、以下のコード例を考えます。
ExecutionContext ecStep = stepExecution.getExecutionContext();
ExecutionContext ecJob = jobExecution.getExecutionContext();
//ecStepとecJobは異なる
コメントにあるように、ecStepとecJobは異なります。この場合は2つの異なるExecutionContextsが存在します。1つはStepのスコープでStepのコミットポイントごとにセーブし、一方、Jobのスコープの方はStep実行の間でセーブします。
1.4. JobRepository
JobRepositoryは上述のすべての機能のための永続化メカニズムです。JobLauncher, Job, Step実装で用いるためのCRUD操作を提供します。Jobをラウンチする時、JobExecutionをリポジトリから取得し、また、実行中には、StepExecutionとJobExecutionの実装をリポジトリに渡すことで永続化をします。
java configurationを使う場合、@EnableBatchProcessingアノテーションのデフォルト設定でJobRepositoryが自動的に登録されます。
1.5. JobLauncher
JobLauncherは、以下例のように、JobParametersを渡してJobを起動するためのインタフェースです。
public interface JobLauncher { public JobExecution run(Job job, JobParameters jobParameters) throws JobExecutionAlreadyRunningException, JobRestartException, JobInstanceAlreadyCompleteException, JobParametersInvalidException; }
このインタフェース実装はJobRepositoryからJobExecutionを取得してJobを実行します。
1.6. Item Reader
ItemReaderは、1回に1アイテム、Stepでの入力を取得するためのインタフェースです。ItemReaderが読み込み可能なアイテムが無くなった事を通知するにはnullを返します。ItemReaderインタフェースの詳細と各種実装についてはReaders And Writersを参照してください。
1.7. Item Writer
ItemWriterは、1回に1チャンクか1バッチ、Stepでの出力を行うためのインタフェースです。通常、ItemWriterは次に受け取るであろう入力に関しては関知せず、現在の呼び出し中に渡されたアイテムのみ処理します。ItemWriterインタフェースの詳細と各種実装についてはReaders And Writersを参照してください。
1.8. Item Processor
ItemProcessorはアイテムにビジネス処理をを行うためのインタフェースです。ItemReaderは1アイテム読み込み、ItemWriterはそれらの書き込み、ItemProcessorはそれ以外のビジネス処理の適用や変換処理のアクセスポイントとなります。なお、アイテム処理中に、アイテムがvalidで無い場合、nullを返すとそのアイテムは書き込みません。ItemProcessorインタフェースの詳細と各種実装についてはReaders And Writersを参照してください。