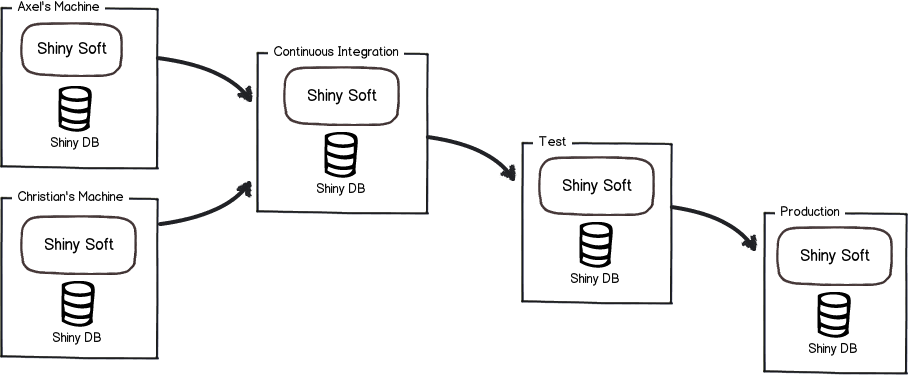
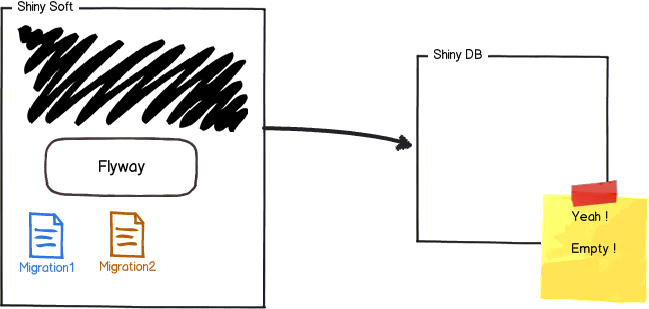
https://flywaydb.org/documentation/ を読んだ。
Overview
Flywayはデータベースマイグレーションをやりやすくします。
Tip: すぐに読み終えられるのでGet Startedセクションを先に目を通すことをオススメします。
Flywayはオープンソースのデータベースマイグレーションツールです。単純さとCoCに特に主眼を置いています。
Flywayは7つの基本コマンド群から構成されています。Migrate, Clean, Info, Validate, Undo, Baseline and Repair.
マイグレーションはSQL(データベース固有の文法(PL/SQL, T-SQL)もサポート)もしくはJava(複雑なデータ変換やLOBの処理など向け)で書きます。
Flywayにはコマンドラインクライアント](https://flywaydb.org/documentation/commandline)があります。JVM上で動かしてアプリケーション開始時にDBをマイグレーションするにはJava API(Android上でも動作)の使用を推奨します。もしくは、Maven pluginやGradle pluginを使います。
上記で不足する場合、Spring Boot, Dropwizard, Grails, Play, SBT, Ant, Griffon, Grunt, Ninjaなどで使えるプラグインがあります。
サポート対象のDBは以下の通りです。Oracle, SQL Server(Amazon RDSとAzure SQL Database含む), DB2, MySQL(Amazon RDS, Azure Database & Google Cloud SQL), MariaDB, PostgreSQL(Amazon RDS, Azure Database, Google Cloud SQL & Heroku含む), Redshift, CockroachDB, SPAP HANA, Sybase ASE, H2, HSQLDB, Derby, SQLLite
Migrations
Overview
FlywaではDBに対するすべての変更をマイグレーション(migrations)と呼びます。マイグレーションはバージョン付き(versiond)かリピータブル(repeatable)の二種類あります。バージョン付きマイグレーションには二つの形式、通常(regular)と取消(undo)、があります。
バージョン付きマイグレーション(Versioned migrations)は、バージョン(version)と説明(description )とチェックサム(checksum)、で構成されます。バージョンは一意にする必要があります。説明は、個々のマイグレーションが何をしているかという、人間向けの単なる情報です。チェックサムは意図しない変更を検出するためのものです。バージョン付きマイグレーションはマイグレーションの基本形です。マイグレーションは一度だけ順番に適用されます。
また、同一バージョンに取消マイグレーション(undo migration)を付けることでそのマイグレーションを取り消し可能にも出来ます。
リピータブルマイグレーション(Repeatable migrations)は説明とチェックサムを持ちますが、バージョンがありません。一度だけ実行するのではなく、代わりに毎回チェックサムの変更が(再)適用されます。
単一のマイグレーション実行では、リピータブルマイグレーションは、すべてのペンディング状態のバージョン付きマイグレーションが実行された後、常に最後に適用されます。リピータブルマイグレーションは説明の順に適用されます*1。
デフォルトではバージョン付き・リピータブルマイグレーションのどちらもSQLかJavaのどちらかで作成可能で、複数のステートメントを書けます。
FlywayはファイルシステムとJavaのクラスパス上のマイグレーションを自動検出します。
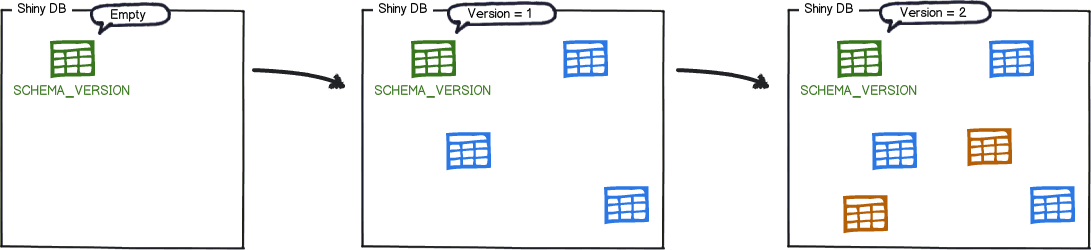
どのマイグレーションがいつ誰によって適用されたかをトラッキングするために、Flywayはスキーマにschema history tableを追加します。
Versioned Migrations
最もよく使うマイグレーションはバージョン付きマイグレーションです。個々のバージョン付きマイグレーションは、バージョン・説明・チェックサム、を持ちます。バージョンは一意にする必要があります。説明は、個々のマイグレーションが何をしているかという、人間向けの単なる情報です。チェックサムは意図しない変更を検出するためのものです。バージョン付きマイグレーションはマイグレーションの基本形です。マイグレーションは一度だけ順番に適用されます。
バージョン付きマイグレーションは基本的には以下の用途に使われます。
- create/alter/drop table,index,foreign keys,enum,UDT
- 参照データの更新(Reference data updates)
- データ修正
以下は一例です。
CREATE TABLE car (
id INT NOT NULL PRIMARY KEY,
license_plate VARCHAR NOT NULL,
color VARCHAR NOT NULL
);
ALTER TABLE owner ADD driver_license_id VARCHAR;
INSERT INTO brand (name) VALUES ('DeLorean');
バージョン付きマイグレーションにはそれぞれに一意のバージョンを割り当てる必要があります。一般的なドット記法に沿えば任意のバージョンが有効です。通常なら単純増加の整数で十分でしょう。ただし、Flywayは柔軟性があり以下のようなバージョン付きマイグレーションの番号が有効です。
- 1
- 001
- 5.2
- 1.2.3.4.5.6.7.8.9
- 205.68
- 20130115113556
- 2013.1.15.11.35.56
- 2013.01.15.11.35.56
バージョン付きマイグレーションはその番号順に適用されます。バージョンは数値としてソートされます。
Undo Migrations
Flyway Pro
取消マイグレーションは通常のバージョン付きマイグレーションの逆です。取消マイグレーションの役割は同一バージョンのマイグレーションの影響を取消すことにあります。取消マイグレーションは無くても良く、通常のバージョン付きマイグレーションの実行時には不要です。
上述の例を取ると、取消マイグレーションは以下のようになります。
DELETE FROM brand WHERE name='DeLorean';
ALTER TABLE owner DROP driver_license_id;
DROP TABLE car;
Important Notes
取消マイグレーションの考え方は魅力的に見えますが、実際には何らかを壊す場合があります。破壊的変更(drop, delete, truncate)はトラブルの元です。そうでないとしても、バックアップから復元するためのお手製のソリューションを十分にテストする羽目になります。
前提として、取消マイグレーションはマイグレーション全体が成功している場合に取消を行うものです。そのためDDLトランザクション無しで失敗したバージョン付きマイグレーションをどうにかすることは出来ません。その理由は、マイグレーションがどの段階で失敗するかは分からないためです。いま10ステートメントあるとして、1,5,7,10番目が失敗するかもしれません。事前にこれを検知する方法はありません。これとは対照的に、取消マイグレーションはバージョン付きマイグレーション全体を取消します。よってそうした状況下をなんとかするものではありません。
我々が推奨する代替案はDBと現行の本番環境にデプロイされているコードの全バージョンとの間に後方互換性を持ち続けるというものです。この場合であればマイグレーションの失敗はトラブルになりません。アプリケーションの旧バージョンはDBと互換性が保たれているので、アプリケーションをロールバックし、調査して、しかるべき処置を行います。
この案は適切で、十分にテストした、バックアップとリストアによって実現します。特定のDBの構造に非依存で、テストして実証が取れたら、マイグレーションスクリプトは何も壊さなくなります。パフォーマンスの最適化には、使用しているインフラストラクチャがサポートしていれば、基底ストレージのスナップショット機能の使用を推奨します。特に大規模データボリュームでは、伝統的なバックアップとリストアよりも格段に高速となる場合があります。
Repeatable Migrations
リピータブルマイグレーションは説明とチェックサムを持ちますが、バージョンがありません。一度だけ実行する代わりに毎回チェックサムの変更が(再)適用されます。
定義を持つデータベースオブジェクトの管理に有用で、バージョン管理下の単一ファイルで扱えるようになります。基本的には以下のように使います。
- view/procedure/function/packeageの(再)生成
- バルクで参照データの再insert
単一のマイグレーション実行中では、ペンディング中のバージョン付きマイグレーションがすべて実行されたあと、リピータブルマイグレーションは常に最後に実行されます。リピータブルマイグレーションはその説明の順序で適用されます。
同一のリピータブルマイグレーションが複数回適用出来るように作成するのはプログラマの責任です。基本的にはDDLステートメントにCREATE OR REPLACEを使います。
リピータブルマイグレーションの例は以下のようになります。
CREATE OR REPLACE VIEW blue_cars AS
SELECT id, license_plate FROM cars WHERE color='blue';
SQL-based migrations
マイグレーションは基本的にSQLで書きます。使い始めやすく、既存のスクリプト、ツールやスキルを流用できます。DBの全機能が使用可能で、中間の変換レイヤーを理解する手間を省けます。
SQLベースのマイグレーションは基本的には以下のように使います。
- DDL(TABLE,VIEW,TRIGGER,SEQUENCEのCREATE/ALTER/DROPステートメント)
- 単純な参照データ変更(参照データテーブルのCRUD)
- 単純なバルクデータ変更(通常データテーブルのCRUD)
Naming
Flywayにマイグレーションファイルを認識させるには、以下のネーミングルールに従う必要があります。
(ここにVersioned Migrations, Undo Migrations, Repeatable Migrationsの図がCSSを駆使して描かれている。本家ページ参照)
https://flywaydb.org/documentation/migrations#naming
ファイル名は以下のパーツで構成されます。
- Prefix: バージョン付きの場合
v(変更), 取消の場合u(変更)、リピータブルの場合R(変更)
- Version: ドットもしくはアンダースコアでバージョンを記述(リピータブルでは不要)
- Separator:
__(アンダースコア2個)(変更)
- Description: 単語はアンダースコアかスペースで区切る。
- Suffix:
.sql(変更)
Discovery
FlywayはファイルシステムとJavaのクラスパス両方でSQLベースのマイグレーションを参照します。マイグレーションはlocationsプロパティが指す一つ以上のディレクトリに置きます。
locationsにfilesystem:プレフィクスを付けるとファイルシステムをターゲットにします。プレフィクス無しかclasspath:を付けるとJavaのクラスパスをターゲットにします。
(ここにCSSを駆使した図解がある。下記URLの本家参照。)
https://flywaydb.org/documentation/migrations#discovery
新しいSQLベースのマイグレーションは実行時に自動的にファイルシステムとJavaクラスパスのスキャンを行います。必要に応じてlocationsを設定する場合、Flywayは設定した命名規約にマッチする新規のSQLマイグレーションを自動的に検出します*2。
スキャンは再帰的に行います。指定ディレクトリ下のすべてのディレクトリが対象となります。
Syntax
Flywayはすべての標準SQLをサポートします。これには以下を含みます。
補足としてOracleの場合、FlywayはSQL*Plus commandsもサポートします。
Placeholder Replacement
標準SQLに加えて、Flywayはプレースホルダによる置換もサポートします。デフォルトでは${myplaceholder}のようなAntスタイルのプレールホルダになります。
環境間の差異を抽象化するのに役立ちます。
Example
サポートしているSQLの一例です。
CREATE TABLE test_user (
name VARCHAR(25) NOT NULL,
PRIMARY KEY(name)
);
INSERT INTO ${tableName} (name) VALUES ('Mr. T');
Java-based migrations
JavaベースのマイグレーションはSQLでの表現が難しい変更をしたい場合に適しています。
基本的には以下のような場合に使います。
- BLOB, CLOBの変更
- 複雑なバルクデータの変更(再計算・複雑なフォーマット変更など)
Naming
Flywayに認識させるには、JavaベースのマイグレーションはJdbcMigrationインタフェースを実装する必要があります。
デフォルトではFlywayはクラス名からバージョンと説明を自動抽出します。そのためには、クラス名は以下のネーミングルールに従う必要があります。
(ここにVersioned Migrations, Undo Migrations, Repeatable Migrationsの図がCSSを駆使して描かれている。本家ページ参照)
https://flywaydb.org/documentation/migrations#naming-1
ファイル名は以下のパーツで構成されます。
- Prefix: バージョン付きの場合
v, 取消の場合u、リピータブルの場合R
- Version: アンダースコア(実行時に自動的にドットで置換される)で区切る。個数は任意(リピータブルでは不要)
- Separator:
__(アンダースコア2個)
- Description: アンダースコア(実行時に自動的にスペースで置換される)で単語を区切る
クラス名にカスタマイズが必要な場合、MigrationInfoProviderインタフェースを実装してデフォルトの規約をオーバーライドします。
オーバーライドによりクラス名を任意に変更できます。バージョン・説明・マイグレーションカテゴリは対応するメソッドの実装で与えます。
Discovery
Flywayはlocationsプロパティが指すパッケージ内のJavaクラスパスにあるマイグレーションを参照します。
(ここにCSSを駆使した図解がある。下記URLの本家参照。)
https://flywaydb.org/documentation/migrations#discovery-1
新しいJavaベースのマイグレーションは実行時にクラスパスのスキャンで自動検出を行います。スキャンは再帰的に行います。あるパッケージのサブパッケージも対象になります。
Checksums and Validation
SQLマイグレーションとは異なり、Javaマイグレーションはデフォルトではチェックサムを持たないのでFlywayのvalidationによる変更検出の対象となりません。これはMigrationChecksumProviderインタフェースの実装により改良できます。getChecksum()メソッドで自前のチェックサムを実装します。これによりチェックサムが保存されてvalidationに使われます。
Sample Class
package db.migration;
import org.flywaydb.core.api.migration.jdbc.JdbcMigration;
import java.sql.Connection;
import java.sql.PreparedStatement;
Example of a Java-based migration.
public class V1_2__Another_user implements JdbcMigration {
public void migrate(Connection connection) throws Exception {
PreparedStatement statement =
connection.prepareStatement("INSERT INTO test_user (name) VALUES ('Obelix')");
try {
statement.execute();
} finally {
statement.close();
}
}
}
Spring support (Optional)
Springの場合、SpringJdbcMigrationインタフェースを実装するという選択肢もあります。JdbcMigrationと同様な動作をしますが、素のJDBCではなくSpringのJdbcTemplateを使える点が異なります。
package db.migration;
import org.flywaydb.core.api.migration.spring.SpringJdbcMigration;
import org.springframework.jdbc.core.JdbcTemplate;
Example of a Spring Jdbc migration.
public class V1_2__Another_user implements SpringJdbcMigration {
public void migrate(JdbcTemplate jdbcTemplate) throws Exception {
jdbcTemplate.execute("INSERT INTO test_user (name) VALUES ('Obelix')");
}
}
Transactions
デフォルトでは、Flywayは単一トランザクションでマイグレーション実行を常にラップします。また、groupプロパティをtrueにすることで、単一トランザクション内にすべてのマイグレーション実行をラップできます*3。
DBのなんらかの技術的制限が原因で、トランザクションで特定のステートメントを実行できないことをFlywayが検出する場合、トランザクションでそのマイグレーションは実行されません。その場合non-transactionalとマーキングされます。
デフォルトでは、トランザクショナルと非トランザクショナルのステートメントを単一マイグレーション実行に混ぜることは出来ません。ただし、mixedをtrueにすることで可能になります。
Important Note
DBがcleanlyなトランザクションDDLステートメントをサポートする場合、失敗マイグレーションは常にロールバックします(ただしnon-transactionalのマーキングが無い場合に限る)。
一方、DBがcleanlyなトランザクションDDLステートメントをサポートしない場合(DDLステートメント前後に暗黙的なコミットを発行する場合など)、Flywayは失敗時にクリーン・ロールバックを実行出来ないので、マイグレーションを失敗とマーキングし、なんらかのマニュアルクリーンアップが必要なことを通知します。
Query Results
Flyway Pro
マイグレーションは第一義にリリースとデプロイ自動化プロセスの一部として実行されるので、SQLの結果を目で確認するケースは稀です。
とはいえ、そういう目視検査が意味を持つ場合も無くはないので、Flyway ProとEnterprise EditionではSELECT(と結果を返すその他のステートメント)実行時に表形式でクエリ結果を表示できます。
どのマイグレーションがいつ誰によって適用されたかをトラッキングするために、Flywayはスキーマにschema history tableを追加します。このテーブルはスキーマに対するすべての変更の実行記録と見なせます。また、マイグレーションのチェックサムと個々のマイグレーションが成功したかどうかも持ちます。
使い方についてはhow Flyway worksのgetting started guideを読んで下さい。
Migration States
マイグレーションはresolvedかappliedのどちらかになります。ResolvedのマイグレーションはFlywayのファイルシステム・クラスパスのスキャナーが検出した
状態です。最初はpendingになります。DBに対して一度でも実行されると、appliedになります。
マイグレーションが成功するとFlywayのschema history tableでsuccessになります。
マイグレーションが失敗し、かつ、DBがDDLトランザクションをサポートする場合、ロールバックしてschema history tableには何も記録されません。
マイグレーションが失敗し、かつ、DBがDDLトランザクションをサポートしない場合、schema history tableはfailedとなり、なんらかのマニュアルクリーンアップが必要かもしれないことを通知します。
取消マイグレーションでバージョン付きマイグレーションが取消された場合はundoneになります。
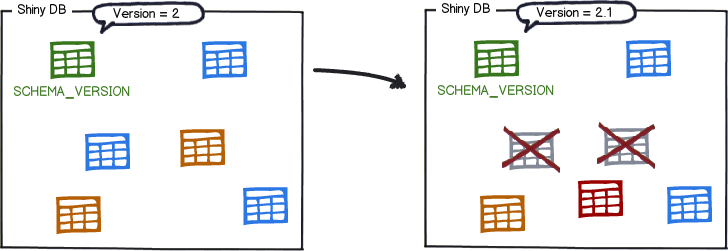
リピータブルマイグレーションが最後に適用された後にチェックサムが変更されている場合はoutdatedになり、再度実行するまでこのままになります。
既知の最も高いバージョンよりも高いappliedのバージョン付きマイグレーション(これは基本的にはソフトウェアの新バージョンが対象スキーマをマイグレートした場合に起きる)をFlywayが参照すると、そのマイグレーションはfutureになります。
Callbacks
マイグレーションはおおよそのニーズを満たしますが、同一のアクションを何度も実行したい場合があります。プロシージャの再コンパイル、マテリアライズドビューの更新、様々なハウスキープ処理など。
そのため、Flywayはコールバックによりライフサイクルにフックをかけられます。
以下がFlywayがサポートするフックです。
コールバックはSQLかJavaのどちらかで実装します。
SQL Callbacks
Flywayのライフサイクルにフックをかける最も簡単な方法はSQLコールバックです。これは設定した場所に命名規約に従ってSQLファイルを単に置くもので、コールバック名の後ろにSQLマイグレーションのサフィックス(※デフォルト.sql)を付けます。
デフォルト設定では、Flywayはデフォルトロケーション(CLIでは<install_dir>/sql)のbeforeMigrate.sql, beforeEachMigrate.sql, afterEachMigrate.sqlなどを参照します。
プレースホルダの置換はSQL migrationsと同様です。
Note: なおFlywayはSQLコールバックスキャンの際にsqlMigrationSuffixesの設定を優先します。
Java Callbacks
SQLコールバックが合わない場合、FlywayCallbackインターフェースを実装することもできます。ライフサイクルに複数のコールバック実装をフックさせることもできます。
More info: Java-based Callbacks
Error Handlers
Flyway Pro
FlywayのSQL実行はDBが返すすべての警告をレポートします。エラーが返される場合Flywayはすべての必要となる詳細を表示し、マイグレーションを失敗にして、可能であればロールバックを自動的に行います。
エラーは基本的に以下のように表示されます。
Migration V1__Create_person_table.sql failed
--------------------------------------------
SQL State : 42001
Error Code : 42001
Message : Syntax error in SQL statement "CREATE TABLE1[*] PERSON "; expected "OR, FORCE, VIEW, ...
Location : V1__Create_person_table.sql (/flyway-tutorial/V1__Create_person_table.sql)
Line : 1
Statement : create table1 PERSON
デフォルトの振る舞いで基本的には充分です。
ただし、以下のようなことをしたい場合があります。
- エラーが既知なので警告として扱い、後でしかるべき処置をしたい。
- 警告をフェイルファーストにしたいのでエラーとして扱い、すぐに問題解決できるようにしたい。
- DBが特定のエラーか警告を出す場合に特定の処理を紐づけたい。
Flyway ProとEnterprise Editionにはこれらを実現するためのエラーハンドラ(Error Handlers)があります。
Implementation
エラーハンドラはorg.flywaydb.core.api.errorhandler.ErrorHandlerインタフェースを実装するJavaクラスです。
このインターフェースにはメソッドが一つ(boolean handle(Context context))あり、DBが警告かエラーを少なくとも一つ返す場合に呼ばれます。インタフェース実装ではエラーや警告を見てそれに応じた処理をします。メッセージのログ出力や、例外のスローが出来ます。trueはエラーと警告が処理されたことを示します。falseはFlywayに次に設定されているErrorHandlerに進ませることを指示し、もし無い場合はデフォルトの振る舞いにフォールバックします。
Configuration
flyway.errorHandlersプロパティに複数のエラーハンドラを設定します。エラーハンドラは設定した順に呼び出されます。一つも設定されていない場合はFlywayはデフォルトの振る舞いにフォールバックします。
Example
Orcleのストアドプロシージャのコンパイルエラーは、デフォルトでは、ドライバは単に警告を出してFlywayはそれを出力します。
DB: Warning: execution completed with warning (SQL State: 99999 - Error Code: 17110)
以下は警告をエラーとして扱うエラーハンドラの例です。
package org.mycompany.mypkg;
import org.flywaydb.core.api.FlywayException;
import org.flywaydb.core.api.errorhandler.Context;
import org.flywaydb.core.api.errorhandler.ErrorHandler;
import org.flywaydb.core.api.errorhandler.Warning;
public class OracleProcedureFailFastErrorHandler implements ErrorHandler {
@Override
public boolean handle(Context context) {
for (Warning warning : context.getWarnings()) {
if ("99999".equals(warning.getState()) && warning.getCode() == 17110) {
throw new FlywayException("Compilation failed");
}
}
return false;
}
}
Flywayには以下のように設定し、
flyway.errorHandlers=org.mycompany.mypkg.OracleProcedureFailFastErrorHandler
OrcleのストアドプロシージャのコンパイルエラーはCompilation failedと即時エラー(immediate error)になります。
Dry Runs
Flyway Pro
FlywayがDBにマイグレーションを実行するときの動きは、適用対象のマイグレーションを参照し、ソートしてDBに対して直接それらを適用します。
デフォルトの振る舞いで基本的には充分です。
ただし、以下のようなことをしたい場合があります。
- FlywayがDBにする予定の変更のプレビュー
- 適用前にDBAにSQLのレビューを依頼
- Flywayで更新されるものを確認し、実際のDB変更は別のツールでやる
Flyway ProとEnterprise Editionにはこれらを実現するためのDry Runsがあります。
Implementation
Dry Runの場合、Flywayはread-onlyでDB接続をセットアップします。Flywayはマイグレーション実行に必要なものを調べ、通常のマイグレーションで実行予定のすべてのステートメントを含む単一のSQLファイルを生成します。このSQLファイルをレビューします。これで十分な場合、FlywayにDBへのマイグレートを指示し、そうするとすべての変更が適用されます。もしくは、Flywayを使わず別のツールでDBに直接dry runのSQLファイルを適用することも出来ます。なお、このSQLファイルにはFlywayのschema history tableの生成と更新に必要なステートメントが含まれており、すべてのスキーマ変更は他同様にトラッキングされます。
この動作は透過的なので、その他のFlywayの機能である、SQL・Javaマイグレーション、バージョン付き・リピータブル、コールバック、取消マイグレーションなどと一緒に使えます。
Configuration
Flywayのcommand-line tool, Maven plugin, Gradle pluginで使う場合、dry runの出力となるSQLファイルはflyway.dryRunOutputプロパティで設定します。
直接APIを使う場合、dry runの出力はjava.io.OutputStreamで設定します。CLIより細かい制御が出来ます。
プロパティを設定するとFlywayのdry runモードが有効になります。DBは変更されなくなり、適用予定のすべてのSQLステートメントがdry runの出力に送られるようになります。