https://docs.spring.io/spring-batch/4.1.x/reference/html/common-patterns.html#commonPatterns
https://qiita.com/kagamihoge/items/12fbbc2eac5b8a5ac1e0 俺の訳一覧リスト
1. Common Batch Patterns
ある種のジョブはSpring Batch標準コンポーネントのみの組み合わせで構築できます。ItemReaderとItemWriterの実装は様々なケースに適用可能です。しかし、基本的には、カスタムコードの実装が必要です。アプリケーション開発者に対するSpring BatchのエントリーポイントはTasklet, ItemReader, ItemWriterと各種リスナーです。シンプルなバッチジョブではSpring BatchのItemReaderを使用出来ますが、ItemWriterやItemProcessorにカスタムの処理な書き込みが必要となる場合があります。
このチャプターでは、カスタムビジネスロジックにおける共通パターンの例について解説します。これらは主としてリスナーを活用します。なお、ItemReaderやItemWriter実装はリスナーも実装可能です。
1.1. Logging Item Processing and Failures
1アイテムごとにstepでエラーハンドリングを行い、特別なチャネルにロギングしたりDBにレコードを追加したり、をするための共通パターンです。chunk指向Step(stepファクトリビーンで生成)では単純に、readエラーはItemReadListener、writeエラーはItemWriteListenerの実装により実現します。以下コードはreadとwriteエラーログ出力するリスナの例です。
public class ItemFailureLoggerListener extends ItemListenerSupport { private static Log logger = LogFactory.getLog("item.error"); public void onReadError(Exception ex) { logger.error("Encountered error on read", e); } public void onWriteError(Exception ex, List<? extends Object> items) { logger.error("Encountered error on write", ex); } }
リスナ実装したら以下例のようにstepに登録します。
Java Configuration
@Bean public Step simpleStep() { return this.stepBuilderFactory.get("simpleStep") ... .listener(new ItemFailureLoggerListener()) .build(); }
※ リスナーのonError()での処理は、後にロールバックされるトランザクション内での処理になります。DBなどトランザクショナルなリソースをonError()で使う場合、リスナーメソッドに宣言的トランザクション(詳細はSpring Core Reference Guide参照)を追加し、propagation attributeをREQUIRES_NEWにしてください。
1.2. Stopping a Job Manually for Business Reasons
Spring BatchにはJobLauncherにstop()がありますが、これはアプリケーションプログラマというよりオペレータが使うものです。ただ、ビジネスロジック内でのジョブ実行停止したい場合がありえます。
一番シンプルな方法はRuntimeExceptionのスローです(無期限リトライやスキップしない例外)。例えば以下ではカスタム例外を使用しています。
public class PoisonPillItemProcessor<T> implements ItemProcessor<T, T> { @Override public T process(T item) throws Exception { if (isPoisonPill(item)) { throw new PoisonPillException("Poison pill detected: " + item); } return item; } }
別の方法としてstepを止めるには、以下例のように、ItemReaderでnullを返します。
public class EarlyCompletionItemReader implements ItemReader<T> { private ItemReader<T> delegate; public void setDelegate(ItemReader<T> delegate) { ... } public T read() throws Exception { T item = delegate.read(); if (isEndItem(item)) { return null; // ここでstep終了 } return item; } }
上の例はCompletionPolicyのデフォルト実装のnullがバッチ完了を意味する挙動を利用しています。より複雑な完了ポリシーを実装してStepに設定するにはSimpleStepFactoryBeanを使用します。
Java Configuration
@Bean public Step simpleStep() { return this.stepBuilderFactory.get("simpleStep") .<String, String>chunk(new SpecialCompletionPolicy()) .reader(reader()) .writer(writer()) .build(); }
また別の方にStepExecutionにフラグを設定し、アイテム処理中にフレームワーク内でStep実装がこれをチェックします。これを実装するには、StepExecutionにアクセスするためにStepListenerを実装してStepに登録します。以下はフラグを設定するリスナーの例です。
public class CustomItemWriter extends ItemListenerSupport implements StepListener { private StepExecution stepExecution; public void beforeStep(StepExecution stepExecution) { this.stepExecution = stepExecution; } public void afterRead(Object item) { if (isPoisonPill(item)) { stepExecution.setTerminateOnly(true); } } }
フラグをセットする場合、デフォルトの振る舞いはstepでJobInterruptedExceptionをスローします。この振る舞いはStepInterruptionPolicyで制御できます。なお、例外スローかしないかの選択肢しか無いので、ジョブは常にabnormal endingになります。
1.3. Adding a Footer Record
フラットファイルに書き込む場合、すべての処理完了後にファイル末尾にフッター行を追加したい場合があります。これはSpring BatchのFlatFileFooterCallbackにより実装できます。FlatFileFooterCallback(と対になるFlatFileHeaderCallback)はFlatFileItemWriterのオプションプロパティで以下のようにwriterに追加します。
Java Configuration
@Bean public FlatFileItemWriter<String> itemWriter(Resource outputResource) { return new FlatFileItemWriterBuilder<String>() .name("itemWriter") .resource(outputResource) .lineAggregator(lineAggregator()) .headerCallback(headerCallback()) .footerCallback(footerCallback()) .build(); }
フッターのコールバックには1つだけメソッドがあり、フッター書き込み時に呼び出されます。
public interface FlatFileFooterCallback { void writeFooter(Writer writer) throws IOException; }
1.3.1. Writing a Summary Footer
フッター行に対するよくある要望に、出力処理中の情報を集約してファイル末尾にそれを追加する、があります。このフッターはファイルの要約やチェックサムに使われます。
例えば、バッチジョブがフラットファイルにTrade行を書き込むとして、全Tradesの総合計をフッターに配置したい場合、ItemWriter実装を以下のようにします。
public class TradeItemWriter implements ItemWriter<Trade>, FlatFileFooterCallback { private ItemWriter<Trade> delegate; private BigDecimal totalAmount = BigDecimal.ZERO; public void write(List<? extends Trade> items) throws Exception { BigDecimal chunkTotal = BigDecimal.ZERO; for (Trade trade : items) { chunkTotal = chunkTotal.add(trade.getAmount()); } delegate.write(items); // アイテム正常書き込み後に総合計を加算 totalAmount = totalAmount.add(chunkTotal); } public void writeFooter(Writer writer) throws IOException { writer.write("Total Amount Processed: " + totalAmount); } public void setDelegate(ItemWriter delegate) {...} }
TradeItemWriterのtotalAmountはTradeアイテム書き込み後に加算します。すべてのTrade処理後、フレームワークはwriteFooterを呼び、ファイルにtotalAmountを挿入します。なお、writeには一時変数chunkTotalがあり、これにchunkのTradeの合計を格納します。これは、writeでskipが発生した場合はtotalAmountを変更しないためです。writeメソッドを最後まで実行し、例外がスローされなかったことを確認できたら、totalAmountを更新します。
writeFooterの使用には、TradeItemWriter(FlatFileFooterCallbackの実装クラス)をfooterCallbackとしてFlatFileItemWriterにワイヤリングします。以下はその方法の例です。
Java Configuration
@Bean public TradeItemWriter tradeItemWriter() { TradeItemWriter itemWriter = new TradeItemWriter(); itemWriter.setDelegate(flatFileItemWriter(null)); return itemWriter; } @Bean public FlatFileItemWriter<String> flatFileItemWriter(Resource outputResource) { return new FlatFileItemWriterBuilder<String>() .name("itemWriter") .resource(outputResource) .lineAggregator(lineAggregator()) .footerCallback(tradeItemWriter()) .build(); }
このTradeItemWriterような作り方はStepが非リスタート可能の場合のみ正しく動作します。これは、このクラスはstateful(totalAmountがある)だが、そのtotalAmountをDBに永続化していないためです。よって、リスタート時にtotalAmountを取得できません。このクラスをリスタート可能にするには、ItemStreamは以下例のようにopenとupdateを実装します。
public void open(ExecutionContext executionContext) { if (executionContext.containsKey("total.amount") { totalAmount = (BigDecimal) executionContext.get("total.amount"); } } public void update(ExecutionContext executionContext) { executionContext.put("total.amount", totalAmount); }
updateメソッドはExecutionContextにtotalAmountの現在値を保存します。openメソッドはExecutionContextからtotalAmountを取得し処理開始時の値として使用し、Stepの前回終了時点からリスタートします。
1.4. Driving Query Based ItemReaders
chapter on readers and writersで、ページングを使用するDB入力について解説しました。DB2など、たいていのDBで、他のオンラインアプリケーションなどで必要なテーブルを読み込む場合、過度の悲観的ロックは問題を起こす場合があります。加えて、過度に大きなデータセットに対するカーソルオープンが特定DBで問題を起こす場合があります。よって、データ読み取りに'Driving Query'を取るプロジェクトがあります。この方針は、以下図のように、返す必要のあるオブジェクト全体ではなく、キーをイテレートする動作をします。
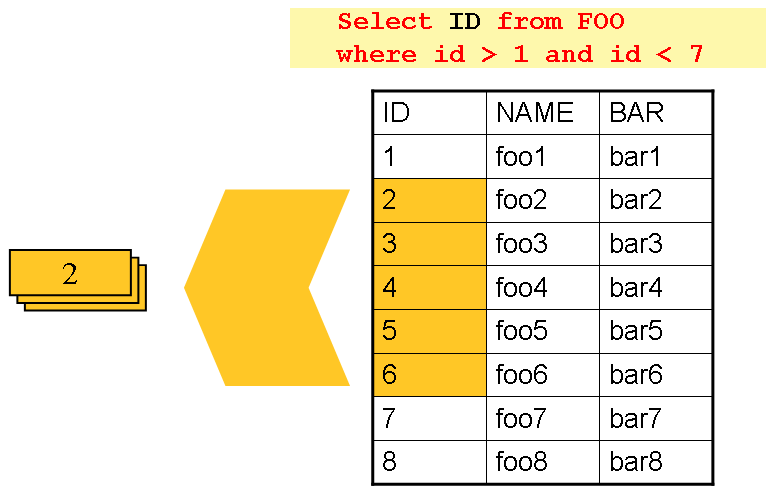
Figure 1. Driving Query Job
上記例は、カーソルベースのサンプルで使用したのと同じ'FOO'テーブルです。ただし、行全体を選択するのではなく、ここのSQLステートメントではIDのみ選択しています。よって、readはFOOオブジェクトではなく、Integerを返します。このIDの数値を使用し、後でFooオブジェクトという"詳細"を取得します。
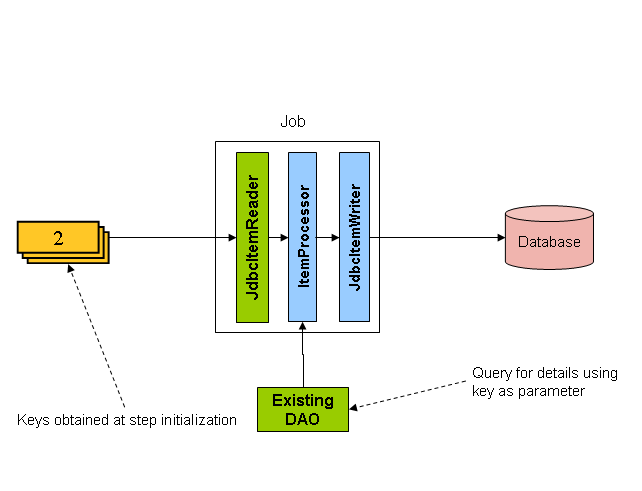
Figure 2. Driving Query Example
ItemProcessorはdriving queryから得たキーを基に'Foo'オブジェクトへと変換します。DAOを使用してキーを基にオブジェクト全体をクエリします。
1.5. Multi-Line Records
基本的にはフラットファイルは各レコードを1行になりますが、レコードを複数のフォーマットで複数行に展開することもあります。以下はそうした展開例の抜粋です。
HEA;0013100345;2007-02-15 NCU;Smith;Peter;;T;20014539;F BAD;;Oak Street 31/A;;Small Town;00235;IL;US FOT;2;2;267.34
1行の開始は'HEA'で始まり、1行の最終行は'FOT'で始まります。これを正しく扱うには以下を考慮する必要があります。
- 1度に1レコード読み込むのでなく、
ItemReaderは複数行レコードのグループとして読み込み、そのグループをItemWriterに渡します。 - 各行の種類ごとにトークン処理を行う。
単一レコードを複数行に展開し、かつ、全体で何行来るかは事前に不明なため、ItemReaderはレコード全体を注意深く読みこむ必要があります。これを行うには、FlatFileItemReaderのラッパーとしてItemReaderを実装します。
Java Configuration
@Bean public MultiLineTradeItemReader itemReader() { MultiLineTradeItemReader itemReader = new MultiLineTradeItemReader(); itemReader.setDelegate(flatFileItemReader()); return itemReader; } @Bean public FlatFileItemReader flatFileItemReader() { FlatFileItemReader<Trade> reader = new FlatFileItemReaderBuilder<Trade>() .name("flatFileItemReader") .resource(new ClassPathResource("data/iosample/input/multiLine.txt")) .lineTokenizer(orderFileTokenizer()) .fieldSetMapper(orderFieldSetMapper()) .build(); return reader; }
各行に応じた適切なトークン分割をするため、特に重要なのは固定幅入力なので、デリゲート先のFlatFileItemReaderに対してPatternMatchingCompositeLineTokenizerを使います。FlatFileItemReader in the Readers and Writers chapterに詳細があります。それから、デリゲート先のreaderは各行をラップ元のItemReaderにFieldSetで返すためにPassThroughFieldSetMapperを使います。
Java Content
@Bean public PatternMatchingCompositeLineTokenizer orderFileTokenizer() { PatternMatchingCompositeLineTokenizer tokenizer = new PatternMatchingCompositeLineTokenizer(); Map<String, LineTokenizer> tokenizers = new HashMap<>(4); tokenizers.put("HEA*", headerRecordTokenizer()); tokenizers.put("FOT*", footerRecordTokenizer()); tokenizers.put("NCU*", customerLineTokenizer()); tokenizers.put("BAD*", billingAddressLineTokenizer()); tokenizer.setTokenizers(tokenizers); return tokenizer; }
ラッパーはレコード終端を解釈する必要があります。よって、レコード終端に達するまで、デリゲート先のreadを繰り返し呼びます。各行を読み込むためには、ラッパーで返すアイテムを組み立てる必要があります。フッターに達すると、アイテムはItemProcessorやItemWriterに渡せるようになります。
private FlatFileItemReader<FieldSet> delegate; public Trade read() throws Exception { Trade t = null; for (FieldSet line = null; (line = this.delegate.read()) != null;) { String prefix = line.readString(0); if (prefix.equals("HEA")) { t = new Trade(); // Record must start with header } else if (prefix.equals("NCU")) { Assert.notNull(t, "No header was found."); t.setLast(line.readString(1)); t.setFirst(line.readString(2)); ... } else if (prefix.equals("BAD")) { Assert.notNull(t, "No header was found."); t.setCity(line.readString(4)); t.setState(line.readString(6)); ... } else if (prefix.equals("FOT")) { return t; // Record must end with footer } } Assert.isNull(t, "No 'END' was found."); return null; }
1.6. Executing System Commands
バッチジョブ内から外部のコマンドを呼ぶ必要があるケースは多いです。そうした処理はスケジューラで別途に開始出来ますが、実行時のメタデータの利点が失われます。また、マルチステップジョブを複数ジョブに分割する必要も発生します。
よくあるケースなので、Spring Batchは以下のようにシステムコマンドを呼ぶTaskletを用意しています。
Java Configuration
@Bean public SystemCommandTasklet tasklet() { SystemCommandTasklet tasklet = new SystemCommandTasklet(); tasklet.setCommand("echo hello"); tasklet.setTimeout(5000); return tasklet; }
1.7. Handling Step Completion When No Input is Found
DBからの取得結果やファイルが0件なケースは良くあります。Stepでは単純に何も処理が無いので0アイテムを読み込んで完了します。Spring Batch標準クラスのItemReaderはすべてデフォルトではこの方針になっています。入力があるのに何も書き込まないのは、混乱を招く場合があります(ファイル名がおかしくなったり、他同様な問題の発生)。For this reason, the metadata itself should be inspected to determine how much work the framework found to be processed. しかし、入力0件が例外的の場合にはどうすれば良いでしょうか。この場合、0件処理のメタデータをプログラム的にチェックして失敗とするのがベストです。これは一般的なユースケースなため、Spring Batchはその機能をリスナーNoWorkFoundStepExecutionListenerで提供しています。定義は以下の通りです。
public class NoWorkFoundStepExecutionListener extends StepExecutionListenerSupport { public ExitStatus afterStep(StepExecution stepExecution) { if (stepExecution.getReadCount() == 0) { return ExitStatus.FAILED; } return null; } }
上のStepExecutionListenerは'afterStep'でStepExecutionのreadCountプロパティで読み込み0件かどうかをチェックします。0件の場合、FAILEDのexit codeでリターンし、Stepは失敗になります。そうでない場合、nullが返され、Stepのステータスは何も変更しません。
1.8. Passing Data to Future Steps
stepから別のstepにデータを渡したい場合が良くあります。これにはExecutionContextを使います。2つのExecutionContexts、StepとJob、はそれぞれ一長一短です。StepのExecutionContextはstep中のみ、JobのExecutionContextはJob全体です。また、StepのExecutionContextはStepのchunkがコミットする際に更新し、JobのExecutionContextはStep終了時にだけ更新します。
このためStep実行中はStepのExecutionContextに全データを保存してください。これによりStep実行中にデータが適切に保存されます。もしデータをJobのExecutionContextに置く場合、Stepの実行中には永続化しません。Stepが失敗するとそのデータはロストします。
public class SavingItemWriter implements ItemWriter<Object> { private StepExecution stepExecution; public void write(List<? extends Object> items) throws Exception { // ... ExecutionContext stepContext = this.stepExecution.getExecutionContext(); stepContext.put("someKey", someObject); } @BeforeStep public void saveStepExecution(StepExecution stepExecution) { this.stepExecution = stepExecution; } }
次以降のStepsでデータを利用可能にするには、step終了後にJobのExecutionContextへ"昇格"の必要があります。Spring BatchではExecutionContextPromotionListenerを使います。このリスナーにはExecutionContextで昇格させたいキーを設定します。また、オプションで、昇格するexit codeのリストパターンも設定出来ます(COMPLETEDがデフォルト)。他リスナー同様、以下サンプルのようにStepに登録します。
Java Configuration
@Bean public Job job1() { return this.jobBuilderFactory.get("job1") .start(step1()) .next(step1()) .build(); } @Bean public Step step1() { return this.stepBuilderFactory.get("step1") .<String, String>chunk(10) .reader(reader()) .writer(savingWriter()) .listener(promotionListener()) .build(); } @Bean public ExecutionContextPromotionListener promotionListener() { ExecutionContextPromotionListener listener = new ExecutionContextPromotionListener(); listener.setKeys(new String[] {"someKey" }); return listener; }
以下サンプルのように、JobのExecutionContextから保存した値を取得するには以下のようにします。
public class RetrievingItemWriter implements ItemWriter<Object> { private Object someObject; public void write(List<? extends Object> items) throws Exception { // ... } @BeforeStep public void retrieveInterstepData(StepExecution stepExecution) { JobExecution jobExecution = stepExecution.getJobExecution(); ExecutionContext jobContext = jobExecution.getExecutionContext(); this.someObject = jobContext.get("someKey"); } }