https://docs.spring.io/spring-batch/4.1.x/reference/html/scalability.html#scalability
https://qiita.com/kagamihoge/items/12fbbc2eac5b8a5ac1e0 俺の訳一覧リスト
1. Scaling and Parallel Processing
大半のバッチ処理はシングルスレッド・シングルプロセスジョブで問題無いので、より複雑な実装を検討する前にそれが要求を満たすかどうかチェックする事をおすすめします。実際のジョブのパフォーマンスを計測し、まず単純な実装で要求を満たせないかを確認します。最近の一般的なハードウェアであれば、数分で数百メガバイトのファイルを読み書き出来ます。
パラレル処理でジョブを実装する場合、Spring Batchにはこのチャプターで解説する各種オプションが存在します。いくつかの機能はこのチャプターでは解説していません。高レベルでは、パラレル処理には2つのモードがあります。
- 単一プロセス、マルチスレッド
- マルチプロセス
同様にこれをカテゴリに落とし込むと、
- Multi-threaded Step(単一プロセス)
- Parallel Steps(単一プロセス)
- Remote Chunking of Step(マルチプロセス)
- Partitioning a Step(単一 or マルチプロセス)
まず、単一プロセスについてみていき、それからマルチプロセスの方法について見ていきます。
1.1. Multi-threaded Step
パラレル処理にする最も簡単な方法はstep設定にTaskExecutorを追加します。
java configurationでは以下サンプルのようにstepにTaskExecutorを追加します。
Java Configuration
@Bean public TaskExecutor taskExecutor(){ return new SimpleAsyncTaskExecutor("spring_batch"); } @Bean public Step sampleStep(TaskExecutor taskExecutor) { return this.stepBuilderFactory.get("sampleStep") .<String, String>chunk(10) .reader(itemReader()) .writer(itemWriter()) .taskExecutor(taskExecutor) .build(); }
このサンプルでは、taskExecutorはTaskExecutorインタフェースを実装するbeanです。TaskExecutorはSpringの標準インタフェースなので、利用可能な実装の詳細についてはSpring User Guideを参照してください。最もシンプルなマルチスレッドなTaskExecutorがSimpleAsyncTaskExecutorです。
上記設定により、read-process-アイテムのchunkのwrite(コミットインターパル)を実行するStepが、それぞれ別スレッドになります。これは、処理アイテムの順序が固定でなくなり、シングルスレッドとは異なりchunkは非連続なアイテムになりうる、という点に注意が必要です。task executorの制限(スレッドプールに戻すかどうかなど)に加えて、taskletにはthrottle limitがあり、このデフォルトは4です。スレッドプールをフルに使うにはこの値を増やしてください。
java configurationの場合はthrottle limitにビルダーでアクセスします。
Java Configuration
@Bean public Step sampleStep(TaskExecutor taskExecutor) { return this.stepBuilderFactory.get("sampleStep") .<String, String>chunk(10) .reader(itemReader()) .writer(itemWriter()) .taskExecutor(taskExecutor) .throttleLimit(20) .build(); }
stepで使う何らかのプーリングするリソース、例えばDataSource、起因でコンカレンシーに制限がかかる場合があります。そうしたリソースのプールには少なくともstepの同時実行step数以上を指定してください。
一般的なバッチのユースケースにおけるマルチスレッドStepの使用には実用上の制限がいくつか存在します。Stepの登場人物(readerやwriterなど)はステートフルです。もし状態がスレッドで分割されていない場合、そのコンポーネントはマルチスレッドStepでは使えません。特に、Spring Batchの標準readerとwriterの大半がマルチスレッド用に設計されていません。しかし、ステートレスかスレッドセーフなreaderとwriterとであれば動作可能で、process indicator(Preventing State Persistence参照)を使用するサンプルがSpring Batch Samplesにあります(parallelJob)。process indicatorはDB入力テーブルで処理済みアイテムをトラッキングするのに使用します。
Spring BatchはItemWriterとItemReaderの実装をいくつか提供しています。基本的には、Javadocでスレッドセーフかそうでないか、コンカレント環境で問題を避けるにはどうすべきか、の記述があります。Javadocに何も情報が無い場合、実装を見て何らかの状態を保持していないか確認してください。readerが非スレッドセーフなら、SynchronizedItemStreamReaderでデコレートするか、自前のsynchronizing delegatorを作成してください。read()同様processとwrite呼び出しを同期化可能で、これらはchunkのうち最も高コストな部分であり、シングルレスレッドよりも高速に完了する可能性があります。
1.2. Parallel Steps
パラレル化したいアプリケーションロジックを分割して独立したstepに出来るのであれば、単一処理内でその部分をパラレル化できます。Parallel Stepの設定は簡単にできます。
java configurationの場合の以下例では、(step1,step2)とstep3をパラレルにしています。
Java Configuration
@Bean public Job job() { return jobBuilderFactory.get("job") .start(splitFlow()) .next(step4()) .build() //builds FlowJobBuilder instance .build(); //builds Job instance } @Bean public Flow splitFlow() { return new FlowBuilder<SimpleFlow>("splitFlow") .split(taskExecutor()) .add(flow1(), flow2()) .build(); } @Bean public Flow flow1() { return new FlowBuilder<SimpleFlow>("flow1") .start(step1()) .next(step2()) .build(); } @Bean public Flow flow2() { return new FlowBuilder<SimpleFlow>("flow2") .start(step3()) .build(); } @Bean public TaskExecutor taskExecutor(){ return new SimpleAsyncTaskExecutor("spring_batch"); }
flowを実行するのに使用するTaskExecutor実装を設定で指定可能です。デフォルトはSyncTaskExecutorですが、パラレルでstepを実行するには非同期のTaskExecutorが必要です。exitステータスとtransitioningの集約前にsplitの各flowが完了する事をjobは保証します。
詳細はSplit Flowsのセクションを参照してください。
1.3. Remote Chunking
remote chunkingでは、Step処理は複数プロセスに分割し、なんらかのミドルウェアを用いて互いに通信します。以下がイメージ図です。
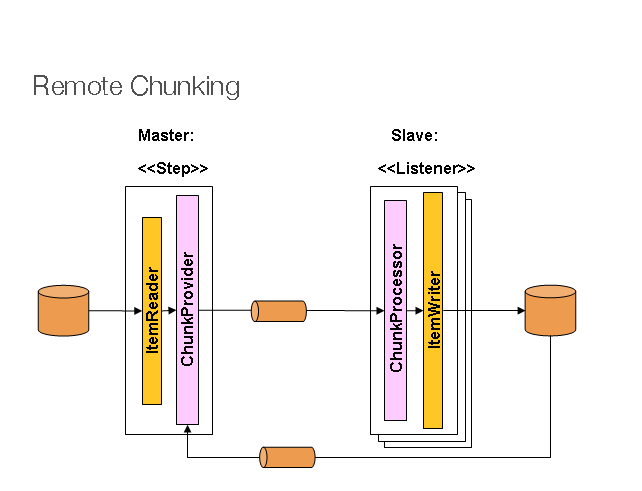
Figure 1. Remote Chunking
マスターコンポーネントは単一プロセスで、スレーブは複数のリモートプロセスです。マスターがボトルネックにならなければこのパターンはベストなので、アイテム読み込みよりも後続処理の方が高コストな構成向きです(実際良くある)
マスターはSpring BatchのStepで、ItemWriterはミドルウェアにアイテムのchunkをメッセージとして何らかの方法で送信するもので置き換えます。スレーブはミドルウェアに応じた標準リスナー(例えば、JMSの場合、MesssageListenerの実装になる)*1で、その役割は、ChunkProcessorを介して、標準ItemWriter, ItemProcessor + ItemWriterでアイテムのchunkを処理することです。このパターンの利点はreader, processor, writerにSpring Batchの標準クラスが使える点です(stepをローカルで実行するのと同じように使える)。アイテムは動的に分割されてミドルウェア経由で共有されるので、リスナがすべてeager consumerの場合、負荷分散は自動的に行われます。
ミドルウェアはdurableで、各メッセージに対する単一コンシューマと配信保証が必要です。この候補は明らかにJMSですが、グリッドコンピューティングと共有メモリプロダクトには他の選択肢(JavaSpacesなど)もあります。
詳細はSpring Batch Integration - Remote Chunkingを参照してください。
1.4. Partitioning
Spring BatchはStepをパーティション化してリモート実行するSPI(Service Provider Interface)もあります。リモートのStepインスタンスはローカルで設定して実行すると同じように使えます。以下がイメージ図です。
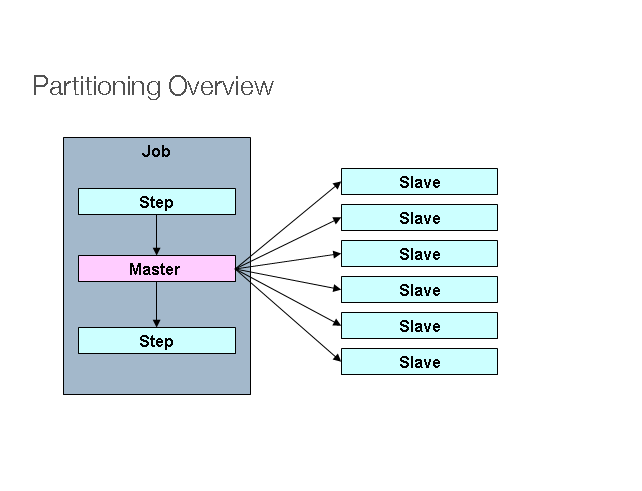
Figure 2. Partitioning
左側のJobはStepインスタンスのシーケンスで、一つのStepがマスターとラベル付けされています。図のスレーブはすべて同一のStepインスタンスで、このStepはマスター側に置くことも可能で、結果も同じになります。スレーブは基本的にはリモートサービスですがローカルスレッドにも出来ます。このパターンでは、マスターからスレーブに送信するメッセージのdurableや配信保証は不要です。JobRepositoryのメタデータがJob実行において各スレーブが一度だけ実行されたことを保証します。
Spring BatchのSPIはStepの実装(PartitionStep)と指定環境用に実装が必要な2つのstrategy interfacesという構成です。strategy interfacesはPartitionHandlerとStepExecutionSplitterで、その役割は以下のシーケンス図の通りです。
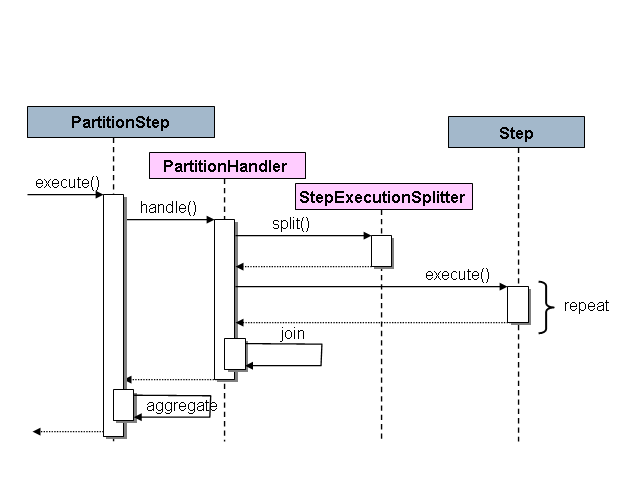
Figure 3. Partitioning SPI
上図右側のStepは"リモート"スレーブ、基本的には、これは多数のオブジェクトで処理を行い、PartitionStepが処理を駆動します。
以下の図はjava configurationでのPartitionStep設定例です。
Java Configuration
@Bean public Step step1Master() { return stepBuilderFactory.get("step1.master") .<String, String>partitioner("step1", partitioner()) .step(step1()) .gridSize(10) .taskExecutor(taskExecutor()) .build(); }
マルチスレッドstepのthrottle-limit同様、grid-sizeでtask executorが単一ステップからのリクエストで飽和する事を防止します。
Spring Batch Samplesのテストスイートにコピーして修正可能なサンプルがあります(Partition*Job.xml)。
Spring Batchは"step1:partition0"の形で次々とパーティションのstepを実行します。一貫性のため"step1:master"でマスターstepを呼びたい場合があります。stepにはエイリアスを指定可能です(id属性の代わりにname属性を指定する)。
1.4.1. PartitionHandler
PartitionHandlerはリモーティングやグリッド環境に関するコンポーネントです。リモートStepインスタンスにStepExecutionリクエストを、DTOなど環境が指定するフォーマットでラップして、送信します。入力データの分割方法やStep結果の集約方法については関知しません。通常、復帰やフェイルオーバーについても関知せず、これは基本的には各環境がそうした機能を備えているためです。Spring Batchはそうした環境とは独立したリスタート機能を提供します。失敗したJobはリスタート可能で、失敗したStepsのみ再実行します。
PartitionHandlerには各環境用の実装を指定します。これには、RMI、EJB、webサービス、JMS、Java Spaces、共有メモリグリッド(TerracottaやCoherenceなど)、グリッド実行環境(GridGainなど)、があります。Spring Batchはプロプライエタリなグリッドやリモーティング環境用の実装は含みません。
なお、Spring Batchには、TaskExecutorを使用してローカルの複数スレッド下でStepを実行するPartitionHandlerの実装があります。TaskExecutorPartitionHandlerがそれです。
TaskExecutorPartitionHandlerはjava configurationで以下例のように明示的に設定します。
Java Configuration
@Bean public Step step1Master() { return stepBuilderFactory.get("step1.master") .partitioner("step1", partitioner()) .partitionHandler(partitionHandler()) .build(); } @Bean public PartitionHandler partitionHandler() { TaskExecutorPartitionHandler retVal = new TaskExecutorPartitionHandler(); retVal.setTaskExecutor(taskExecutor()); retVal.setStep(step1()); retVal.setGridSize(10); return retVal; }
gridSizeはstep数を決定するので、これはTaskExecutorのスレッドプールサイズに合わせます。使用可能なスレッド数より大きい値も設定可能で、これにより作業ブロックが小さくなります(which makes the blocks of work smaller.)。
TaskExecutorPartitionHandlerはIOバウンドのStepインスタンスで有効で、たとえば大規模ファイルのコピーやファイルシステムからコンテンツ管理システムへのレプリケートなど、などです。また、Step実装をリモート実行するプロキシにすることも可能です(Spring Remotingなど)。
1.4.2. Partitioner
Partitionerはシンプルな責務を持ちます。新規step実行(リスタート考慮の必要が無い)の入力パラメータとしてexecution contextを生成します。以下インタフェース定義のように一つのメソッドを持ちます。
public interface Partitioner { Map<String, ExecutionContext> partition(int gridSize); }
このメソッドの戻り値はstep実行のユニーク名とExecutionContext形式の入力パラメータを関連付けます。この名前はパーテーション化したStepExecutionsのstep名としてバッチメタデータに出現します。ExecutionContextはname-valueの保存場所と見なせるので、主キー範囲・行番号・入力ファイルの位置、を持ちます。リモートStepは通常、次セクションで解説するように、#{…}でコンテキスト入力にバインドします(stepスコープに遅延バインディング)。
step実行の名前(Partitionerが返すMapのキー)はJobの全step実行でユニークにする必要がありますが、他に制限はありません。最も単純な命名(かつユーザが識別しやすい)はプレフィクス+サフィックス命名規約で、プレフィクスは実行step名(Jobでユニーク)で、サフィックスはカウンタにします。Spring BatchのSimplePartitionerはこの規約に沿います。
PartitionNameProviderでパーティションとは別のパーティション名を返すためのインタフェースを使うことも出来ます。Partitionerがこれを実装する場合、リスタートすると、その名前だけをクエリします(only the names are queried)。パーティショニングが高コストの場合はこれは最適化に役立ちます。PartitionNameProviderが返す名前はPartitionerと一致する必要があります。
1.4.3. Binding Input Data to Steps
PartitionHandlerで同一の設定でstepを実行し、そのstepにExecutionContextから実行時に入力パラメータをバインドすることは、非常に便利です。これはSpring BatchのStepScope機能で簡単に実現できます(Late Bindingで解説)。例えば、Partitionerが生成するExecutionContextを、キーfileNameでstepごとに異なるファイル(やディレクトリ)を指す場合、Partitionerは以下表のような内容になります。
Table 1. Example step execution name to execution context provided by Partitioner targeting directory processing
| Step Execution Name (key) | ExecutionContext (value) |
|---|---|
| filecopy:partition0 | fileName=/home/data/one |
| filecopy:partition1 | fileName=/home/data/two |
| filecopy:partition2 | fileName=/home/data/three |
Java Configuration
これにより、以下サンプルのように、execution contextにファイル名は遅延バインディングでstepにバインドされます。
@Bean public MultiResourceItemReader itemReader( @Value("#{stepExecutionContext['fileName']}/*") Resource [] resources) { return new MultiResourceItemReaderBuilder<String>() .delegate(fileReader()) .name("itemReader") .resources(resources) .build(); }
*1:The slaves are standard listeners for whatever middleware is being used