https://docs.spring.io/spring-batch/4.1.x/reference/html/step.html#configureStep
https://qiita.com/kagamihoge/items/12fbbc2eac5b8a5ac1e0 俺の訳一覧リスト
1. Configuring a Step
ドメインのチャプターで解説したように、Stepは、バッチjobのシーケンシャルで独立したフェーズをカプセル化したもので、バッチ処理の制御と定義に必要なすべての情報を持ちます。Stepの中身はJobを書く開発者次第なため、やや曖昧な説明になっています。Stepは開発者次第でシンプルにも複雑にもなります。シンプルなStepはファイルからDBにロードし、要求されるコードは少しかゼロです(実装次第)。複雑なStepは、以下イメージ図のような、複雑なビジネスルール処理の一部になるものがあります。
Figure 1. Step
1.1. Chunk-oriented Processing
Spring Batchは一般的な実装スタイルのうちチャンク指向処理スタイルを使います。チャンク指向の処理は、1度に1データ読み取ってトランザクション境界内で書き込むチャンクを作成します。ItemReaderから1アイテム読み、ItemProcessorに渡し、集約します。読み込んだアイテム数がコミット間隔に達すると、ItemWriterがチャンクを書き込み、トランザクションをコミットします。以下のイメージが一連の処理です。
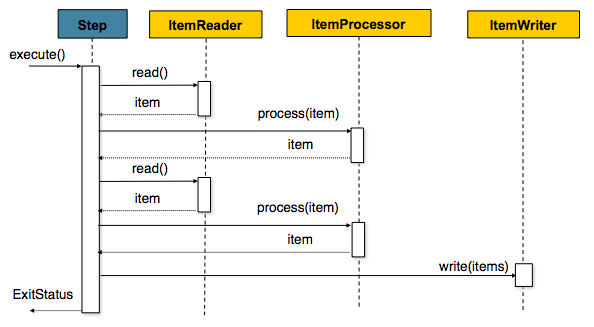
Figure 2. Chunk-oriented Processing
以下のコードは概念を示すコードです。
List items = new Arraylist(); for(int i = 0; i < commitInterval; i++){ Object item = itemReader.read() Object processedItem = itemProcessor.process(item); items.add(processedItem); } itemWriter.write(items);
1.1.1. Configuring a Step
Stepの依存性のリストは比較的短いですが、多くの関連クラスを持つ場合があるので非常に複雑です。
java設定の場合、以下例のように、Spring Batchのビルダーが使えます。
Java Configuration
/** * JobRepositoryは基本的にはautowiredされるので明示的な設定は不要です。 */ @Bean public Job sampleJob(JobRepository jobRepository, Step sampleStep) { return this.jobBuilderFactory.get("sampleJob") .repository(jobRepository) .start(sampleStep) .build(); } /** * TransactionManagerは基本的にはautowiredされるので明示的な設定は不要です。 */ @Bean public Step sampleStep(PlatformTransactionManager transactionManager) { return this.stepBuilderFactory.get("sampleStep") .transactionManager(transactionManager) .<String, String>chunk(10) .reader(itemReader()) .writer(itemWriter()) .build(); }
上の設定はアイテム指向stepを作るのに必要な依存性だけを入れています。
reader: processorにアイテムを与えるItemReader。writer:ItemReaderからのアイテムを処理するItemWritertransactionManager: トランザクションの開始とコミットをするSpringのPlatformTransactionManagerrepository:JobRepositoryは定期的にStepExecutionとExecutionContextを保存する(コミットの直前)。chunk: ここではアイテムベースのstepを意味し、トランザクションコミットの処理アイテム数を指定している。
なお、repositoryのデフォルトのbeanはjobRepositoryでtransactionManagerはtransactionManger(どちらも@EnableBatchProcessingで自動設定されます)。また、ItemProcessorは無くても良く、これによりアイテムをreaderからwriterに直接渡せます。
1.1.3. The Commit Interval
前述の通り、stepはアイテムを読んで書き込み、設定したPlatformTransactionManagerで定期的にコミットします。commit-intervalが1の場合、1アイテム書き込むたびにコミットします。ただ、トランザクションの開始とコミットは高コストなので、多くの場合にこれは理想的とは言えません。理想的には、各トランザクションでなるべく多数のアイテム処理するのが好ましく、これはstepが相互作用するリソースと処理データの特性に完全に依存します。このため、あるコミットで処理するアイテム数は変更可能です。以下の例はcommit-intervalが10のtaskletのstepです。
Java Configuration
@Bean public Job sampleJob() { return this.jobBuilderFactory.get("sampleJob") .start(step1()) .end() .build(); } @Bean public Step step1() { return this.stepBuilderFactory.get("step1") .<String, String>chunk(10) .reader(itemReader()) .writer(itemWriter()) .build(); }
上の例では、各トランザクションで10アイテム処理します。処理開始時にトランザクションが開始します。そして、各アイテムをItemReaderのreadで読むたびにカウンターがインクリメントします。10に達すると、集約アイテムのリストをItemWriterに渡し、トランザクションをコミットします。
Configuring a Step for Restart
Configuring and Running a JobではJobのリスタートについて解説しました。リスタートは様々な影響をstepに与えるため、従って、何らかの設定が必要となります。
Setting a Start Limit
Stepの最大実行回数を制御したい場合があります。たとえば、ある特定のStepがリソースを無効化して再実行前に手動で戻す必要があるので、一度だけ実行するようにしたい、などです。設定はstepレベルで行い、異なるstepで異なる設定が可能です。一度しか実行出来ないStepは、制限無しのStepがあるJobと一緒に入れられます。以下のコード例はstart limit設定の例です。
Java Configuration
@Bean public Step step1() { return this.stepBuilderFactory.get("step1") .<String, String>chunk(10) .reader(itemReader()) .writer(itemWriter()) .startLimit(1) .build(); }
上のstepは一度だけ実行可能です。再実行するとStartLimitExceededExceptionをスローします。なお、start-limitのデフォルト値はInteger.MAX_VALUEです。
Restarting a Completed Step
restartable jobの場合、初めは成功したかどうかに関わらず、常に実行したいstepがある場合があります。validation stepや処理前にリソースのクリーンアップをするStepなどです。restarted jobの通常処理では、正常終了したことを示す'COMPLETED'ステータスとなり、これはスキップします。allow-start-if-completeを"true"に設定するとその挙動をオーバーライドして常に実行するようになります。以下が例です。
Java Configuration
@Bean public Step step1() { return this.stepBuilderFactory.get("step1") .<String, String>chunk(10) .reader(itemReader()) .writer(itemWriter()) .allowStartIfComplete(true) .build(); }
Step Restart Configuration Example
以下はリスタート可能なstepを持つjobの設定例です。
Java Configuration
@Bean public Job footballJob() { return this.jobBuilderFactory.get("footballJob") .start(playerLoad()) .next(gameLoad()) .next(playerSummarization()) .end() .build(); } @Bean public Step playerLoad() { return this.stepBuilderFactory.get("playerLoad") .<String, String>chunk(10) .reader(playerFileItemReader()) .writer(playerWriter()) .build(); } @Bean public Step gameLoad() { return this.stepBuilderFactory.get("gameLoad") .allowStartIfComplete(true) .<String, String>chunk(10) .reader(gameFileItemReader()) .writer(gameWriter()) .build(); } @Bean public Step playerSummarization() { return this.stepBuilderFactor.get("playerSummarization") .startLimit(2) .<String, String>chunk(10) .reader(playerSummarizationSource()) .writer(summaryWriter()) .build(); }
上の設定例のjobは、フットボールのデータロードしてサマリをします。3つのstep、playerLoad, gameLoad, playerSummarizationがあります。playerLoadはフラットファイルからプレイヤーデータをロードし、gameLoadは同様にゲームデータをロードします。最後に、playerSummarizationは、ゲームをベースに各プレイヤーの統計を出力します。ここでの想定は、playerLoadのファイルロードは一度だけにしたいが、gameLoadはゲームデータをディレクトリからファイルで取得し、DBに正常ロード後はそのファイルを削除する、とします。この場合、playerLoadは特に設定を必要としません。何度でも実行可能ですが、completeになると、以降はスキップします。しかしgameLoadは最終実行以降にファイルが追加された場合は都度実行の必要があります。毎回実行するために'allow-start-if-complete'を'true'にしています。(DBのgamesテーブルはprocess indicatorを持ち、次のsummarization stepでその新規ゲームデータを参照可能になっている、という想定)。summarization stepはこのjobで最も重要で、start limitは2にしています。stepが連続して失敗し、job実行を制御するオペレータにexit codeを返します。そして、手動変更しない限り再開は出来なくなります。
※ 本ドキュメントのjob例はサンプルプロジェクトのfootballJobとは異なります。
このセクションのまとめとしてfootballJobの例を3回実行したときに起きることを解説します。
Run 1:
playerLoadを実行すると正常終了し、'PLAYERS'テーブルに400プレイヤー追加する。gameLoadを実行するとゲームデータの11ファイルを処理し、'GAMES'テーブルにロードする。playerSummarizationを開始すると5分後に失敗する。
Run 2:
playerLoadは既に正常終了済みなので実行しない。allow-start-if-completeは'false'(デフォルト)gameLoadは再実行して更に別の2ファイルを処理し、前回様に'GAMES'テーブルにロードする(このデータについてはprocess indicatorが未処理となる)。playerSummarizationはすべての残ゲームデータ(process indicatorでフィルタリング)を処理開始して30分後に失敗する。
Run 3:
playerLoadは既に正常終了済みなので実行しない。allow-start-if-completeは'false'(デフォルト)gameLoadは再実行して更に別の2ファイルを処理し、前回様に'GAMES'テーブルにロードする(このデータについてはprocess indicatorが未処理となる)。playerSummarizationは開始せずjobが即時killされる。この時点でplayerSummarizationは3回目で、リミットが2なため。リミットを上げるか、そのJobで新規のJobInstanceを作る必要がある。
1.1.5. Configuring Skip Logic
エラーが発生してもStepを失敗にはせず、代わりにスキップしたい場合があります。基本的には、そこでのデータや事象の意味を理解する人が決定します。たとえば、金融データでは、送金は完全に実行する必要あるので、スキップ可能でないものもあります。一方、ベンダーリストのロードは、スキップ可能な場合があります。フォーマット間違いや必須情報の漏れでロード出来ない場合、おおむねスキップで問題ありません。たいていの場合、こうした不正レコードはログ出力します。これについては後に述べるリスナーで処理します。
以下はskip limitの使用例です。
Java Configuration
@Bean public Step step1() { return this.stepBuilderFactory.get("step1") .<String, String>chunk(10) .reader(flatFileItemReader()) .writer(itemWriter()) .faultTolerant() .skipLimit(10) .skip(FlatFileParseException.class) .build(); }
上の例ではFlatFileItemReaderを使用しています。この場合、どの段階においても、FlatFileParseExceptionをスローするとそのアイテムはスキップされてskip limit合計10に対してカウントアップします。step実行中のread, process, writeのスキップ数は別々にカウントしますが、limitはその全スキップに対して適用します。skip limitに達すると、次の例外スローでstepは失敗します。つまり、11回のスキップが例外をトリガするが、10回ではありません(the eleventh skip triggers the exception, not the tenth.)。
上の例の問題点としては、FlatFileParseException以外のその他すべての例外でJobは失敗になります。場合によってはこれは正しい動作となります。しかし、さらに場合によっては、失敗させる例外を指定してその他の全例外はスキップする方が簡単な場合があります。以下はその例です。
Java Configuration
@Bean public Step step1() { return this.stepBuilderFactory.get("step1") .<String, String>chunk(10) .reader(flatFileItemReader()) .writer(itemWriter()) .faultTolerant() .skipLimit(10) .skip(Exception.class) .noSkip(FileNotFoundException.class) .build(); }
スキップ可能例外クラスにjava.lang.Exceptionを指定することで、すべてのExceptionsをスキップ可能に指定しています。ただし、'除外'としてjava.io.FileNotFoundExceptionを指定することで、すべてのExceptionsからFileNotFoundExceptionを除外した設定になります。もしその除外した例外が発生する(つまりスキップ不能な例外)はfatalになります。
例外発生時において、スキップ可能かどうかはクラス階層上の最も近いスーパークラスが決定します。未分類の例外は'fatal'扱いになります。
skipとnoSkipの呼び出し順序は特に意味を持ちません。
1.1.6. Configuring Retry Logic
たいていの場合、例外はskipするかStep失敗のどちらかにします。ただし、すべての例外が決定的なわけではありません。いま、読み込み中にFlatFileParseExceptionをスローする場合、そのレコードに対しては常に例外をスローします。ItemReaderのリセットは無意味です。対して、DeadlockLoserDataAccessExceptionなど、プロセスが別のプロセスでロックするレコードの更新をしようとする場合などは、待機して再試行すれば成功します。この場合、以下のようにリトライを設定します。
@Bean public Step step1() { return this.stepBuilderFactory.get("step1") .<String, String>chunk(2) .reader(itemReader()) .writer(itemWriter()) .faultTolerant() .retryLimit(3) .retry(DeadlockLoserDataAccessException.class) .build(); }
Stepでは、リトライ可能なアイテム数と、リトライ可能な例外リストを設定可能です。リトライの挙動の詳細についてはretryを参照してください。
1.1.7. Controlling Rollback
デフォルトでは、リトライかスキップかを問わず、ItemWriterがスローする例外はStepで制御するトランザクションをロールバックさせます。スキップを前述のように設定する場合、ItemReaderがスローする例外はロールバックになりません。ただし、ItemWriterの例外でロールバックできないケースは色々考えられますが、これはトランザクションを無効にするアクションが無い場合があるためです。このため、以下例のように、ロールバックをしない例外リストをStepに設定可能です。
Java Configuration
@Bean public Step step1() { return this.stepBuilderFactory.get("step1") .<String, String>chunk(2) .reader(itemReader()) .writer(itemWriter()) .faultTolerant() .noRollback(ValidationException.class) .build(); }
Transactional Readers
ItemReaderの基本的な役割は直線的で戻ることは無いです。stepはreaderの入力をバッファし、これはロールバック時にアイテムをreaderから再読み込みする必要を無くすためです。しかし、JMSキューなど、readerがトランザクショナルリソースの一番最初に置かれるケースがあるにはあります。この場合、キューがロールバックするトランザクションに関連付けられるので、キューからプル済みのメッセージは戻されます。このため、下記例のように、アイテムをバッファしないstepを設定可能です。
Java Configuration
@Bean public Step step1() { return this.stepBuilderFactory.get("step1") .<String, String>chunk(2) .reader(itemReader()) .writer(itemWriter()) .readerIsTransactionalQueue() .build(); }
1.1.8. Transaction Attributes
トランザクション属性(Transaction attributes)は、isolation, propagation, timeout、の設定を制御するのに使います。詳細についてはSpring core documentationを参照してください。以下のサンプルではisolation, propagation, timeoutのトランザクション属性を設定しています。
Java Configuration
@Bean public Step step1() { DefaultTransactionAttribute attribute = new DefaultTransactionAttribute(); attribute.setPropagationBehavior(Propagation.REQUIRED.value()); attribute.setIsolationLevel(Isolation.DEFAULT.value()); attribute.setTimeout(30); return this.stepBuilderFactory.get("step1") .<String, String>chunk(2) .reader(itemReader()) .writer(itemWriter()) .transactionAttribute(attribute) .build(); }
1.1.9. Registering ItemStream with a Step
stepはライフサイクルの必要時点でItemStreamのコールバックを処理する必要があります。(ItemStreamインタフェースの詳細についてはItemStreamを参照)。これはstepが失敗してリスタート可能にする必要がある場合は必須で、その理由は、ItemStreamはstepで必要な実行間の永続化状態を取得する場所なためです。
ItemReader, ItemProcessor, ItemWriterがItemStreamを実装すると、それらは自動登録されます。それ以外のstreamは別途登録します。このstreamは間接的な依存性、デリゲートなど、になる事が多く、readerとwriterにインジェクションされます。streamは、以下例のように、'streams'要素でStepに登録します。
Java Configuration
@Bean public Step step1() { return this.stepBuilderFactory.get("step1") .<String, String>chunk(2) .reader(itemReader()) .writer(compositeItemWriter()) .stream(fileItemWriter1()) .stream(fileItemWriter2()) .build(); } /** * Spring Batch 4では、CompositeItemWriterはItemStreamを実装しているので以下は不要ですが * 例として作成しています。 */ @Bean public CompositeItemWriter compositeItemWriter() { List<ItemWriter> writers = new ArrayList<>(2); writers.add(fileItemWriter1()); writers.add(fileItemWriter2()); CompositeItemWriter itemWriter = new CompositeItemWriter(); itemWriter.setDelegates(writers); return itemWriter; }
上記のサンプルでは、CompositeItemWriterはItemStreamではありませんが、デリゲート先に処理を任せます。このため、デリゲート先のwriterはフレームワーク側で正しく認識出来るようにstreamとして明示的に登録の必要があります。ItemReaderはstreamとしての明示的な登録は必要ありませんが、これはStepのプロパティとして直接指定しているためです。上記のstepはリスタート可能で、readerとwriterの状態は失敗イベント時に正しく永続化されます。
1.1.10. Intercepting Step Execution
Job同様、Step実行中には様々なイベントが発生し、そこでユーザが何らかの機能を実行したい場合があります。たとえば、フッターが必要なフラットファイルを書き出すには、フッターを書き込めるように、Step完了時にItemWriterへ通知の必要があります。是の実現にはStepスコープのリスナの一つを使います。
StepListener(これ自体はマーカーに過ぎない)の拡張の一つを実装するクラスはlisteners要素でstepに適用します。listeners要素は、step, tasklet, chunk、で妥当です。なお、そのリスナ関数を適用するレベルに対し宣言することを推奨します。もし単一クラスで複数リスナ(StepExecutionListenerとItemReadListenerなど)を兼ねる場合、最も細かいレベルで宣言します。以下はchunkにリスナを適用する例です。
Java Configuration
@Bean public Step step1() { return this.stepBuilderFactory.get("step1") .<String, String>chunk(10) .reader(reader()) .writer(writer()) .listener(chunkListener()) .build(); }
<step>要素もしくは*StepFactoryBeanファクトリの一つを使用する場合で、ItemReader, ItemWriter, ItemProcessor自身がStepListenerの一つを実装しているとStepに自動登録されます。これはStepに直接インジェクションするコンポーネントにだけ適用されます。もしリスナが別コンポーネント内にネストする場合、明示的な登録が必要です(Registering ItemStream with a Stepで解説)。
StepListenerインタフェースに加えて、同様な処理のためのアノテーションがあります。POJOにこれらアノテーションを付与するメソッドを持たせると、対応するStepListenerに変換します。ItemReader, ItemWriter, Taskletなどchunkコンポネントの実装にそうしたアノテーションを付与するのが良くある使い方です。このアノテーションは、<listener/>要素用のXMLパーサーがアナライズするように、ビルダーのlistenerでも登録をします。よって、stepにリスナーを登録するには、XML namespaceかビルダーのどちらかを使えば良い、ということです。
StepExecutionListener
StepExecutionListenerはStep実行における最も汎用的なリスナーです。Step開始・終了後に、完了・失敗に関わらず、通知を受けます。例は以下の通りです。
public interface StepExecutionListener extends StepListener { void beforeStep(StepExecution stepExecution); ExitStatus afterStep(StepExecution stepExecution); }
afterStepの戻り値型ExitStatusによってリスナーでStepの完了コードを修正可能です。
このインタフェースに対応するアノテーションは以下です。
@BeforeStep@AfterStep
ChunkListener
chunkはトランザクションスコープ内で処理するアイテムとして定義します。コミットインターパルで、トランザクションをコミットすると、chunkをコミットします。ChunkListenerはchunk処理開始かchunk正常処理完了後にロジックを挟むのに使います。以下がインタフェースです。
public interface ChunkListener extends StepListener { void beforeChunk(ChunkContext context); void afterChunk(ChunkContext context); void afterChunkError(ChunkContext context); }
beforeChunkメソッドはトランザクション開始後でItemReaderのread呼び出し前に呼ばれます。逆に、afterChunkメソッドはchunkコミット後によばれます(ロールバックが起きてない場合に限る)。
このインタフェースに対応するアノテーションは以下です。
@BeforeChunk@AfterChunk@AfterChunkError
ChunkListenerはchunk宣言が無い場合にも適用可能です。TaskletStepはChunkListenerを呼ぶ責任があるため、非アイテム指向のtaskletにも同様に適用します(taskletの前後に呼ばれる)。
ItemReadListener
前述のskip logicで解説したように、スキップレコードを後々追えるようにログを残すと有益な場合がある、と述べました。読込エラーの場合には、以下インタフェース定義に示す、ItemReaderListenerで実現できます。
public interface ItemReadListener<T> extends StepListener { void beforeRead(); void afterRead(T item); void onReadError(Exception ex); }
beforeReadメソッドはItemReaderの毎回のread呼び出しの前に呼ばれます。afterReadはreadが正常に完了して読みだしたアイテムを次に渡し終えた後に呼ばれます。読み出し中に何らかのエラーが発生した場合、onReadErrorメソッドが呼ばれます。発生した例外をログ出力するなどが可能です。
このインタフェースに対応するアノテーションは以下です。
@BeforeRead@AfterRead@OnReadError
ItemProcessListener
ItemReadListener同様、アイテムのprocess処理も、以下インタフェース定義に示すような形で、リッスンが可能です。
public interface ItemProcessListener<T, S> extends StepListener { void beforeProcess(T item); void afterProcess(T item, S result); void onProcessError(T item, Exception e); }
beforeProcessメソッドはItemProcessorのprocess前で処理アイテムを渡す前に呼ばれます。afterProcessメソッドはアイテム正常処理後に呼ばれます。処理中にエラーが発生した場合、onProcessErrorメソッドが呼ばれます。発生した例外とそこで処理対象だったアイテムが渡されるので、それをログ出力などします。
このインタフェースに対応するアノテーションは以下です。
@BeforeProcess@AfterProcess@OnProcessError
ItemWriteListener
アイテム書き込みのリッスンはItemWriteListenerで行い、そのインタフェース定義は以下の通りです。
public interface ItemWriteListener<S> extends StepListener { void beforeWrite(List<? extends S> items); void afterWrite(List<? extends S> items); void onWriteError(Exception exception, List<? extends S> items); }
beforeWriteメソッドはItemWriterのwrite前で書き込みアイテムリストを渡す前に呼ばれます。afterWriteメソッドはアイテム正常書き込み後に呼ばれます。エラーが発生した場合、onWriteErrorメソッドが呼ばれます。発生した例外と書き込み対象アイテムが渡されるので、それをログ出力などします。
このインタフェースに対応するアノテーションは以下です。
@BeforeWrite@AfterWrite@OnWriteError
SkipListener
ItemReadListener, ItemProcessListener, ItemWriteListenerはいずれもエラー通知の機構を備えますが、スキップしたレコードについての情報は得られません。たとえば、onWriteErrorは、アイテムがリトライして成功したとしても呼ばれます(is called even if an item is retried and successful.)。このため、スキップしたアイテムをトラッキングするために別のインターフェスが存在し、以下のようなインタフェース定義になります。
public interface SkipListener<T,S> extends StepListener { void onSkipInRead(Throwable t); void onSkipInProcess(T item, Throwable t); void onSkipInWrite(S item, Throwable t); }
onSkipInReadは読み込み中にスキップしたアイテムがあれば呼ばれます。ロールバックすると、複数回スキップにより同一アイテムを登録する場合があることに注意してください(It should be noted that rollbacks may cause the same item to be registered as skipped more than once.)。onSkipInWriteは書き込み中にアイテムスキップした場合に呼ばれます。アイテムは正常に読み込まれている(かつ未スキップ)ので、引数にそのアイテムが渡されます。
このインタフェースに対応するアノテーションは以下です。
@OnSkipInRead@OnSkipInWrite@OnSkipInProcess
SkipListeners and Transactions
SkipListenerの最もよくある使い方はスキップアイテムのログ出力で、このログは別のバッチ処理かあるいは人間がスキップとなった原因を修正したり調査するのに使います。大本のトランザクションがロールバックとなるケースは多数考えられ、Spring Batchは以下2点を保証します。
- 適切なスキップメソッド(発生するエラーのタイミングに依存)がアイテムごとに1度だけ呼ばれる。
SkipListenerはトランザクションコミット前に必ず常に呼ばれる。これにより、リスナーで呼ぶなんらかのトランザクショナルリソースがItemWriterでの失敗によってロールバックしないようにしています。
1.2. TaskletStep
chunk指向処理だけがStepの唯一の処理方法ではありません。Stepがシンプルにストアド呼び出しするだけの場合はどうでしょうか。ItemReaderで呼び出してストアド実行後にnullを返すような作りには出来ます。しかし、これは少々不自然で、何もしないItemWriterを作らなければなりません。Spring BatchではこうしたケースではTaskletStepを使います。
Taskletはexecuteという1つのメソッドを持つシンプルなインタフェースで、TaskletStepが反復呼び出しを行い、RepeatStatus.FINISHEDを返すか失敗を示す例外をスローするまで実行します。Taskletの毎回の呼び出しはトランザクションでラップします。Taskletの実装者は、ストアド・スクリプト・シンプルなSQL更新、などを行います。
TaskletStepを作成するには、ビルダーのtaskletメソッドにTaskletを実装したbeanを渡します。TaskletStepをビルダーで作る際にはchunkを呼ぶ必要はありません。以下はシンプルなtaskletの例です。
@Bean public Step step1() { return this.stepBuilderFactory.get("step1") .tasklet(myTasklet()) .build(); }
※ TaskletStepはもしtaskletがStepListenerを実装する場合はStepListenerとしても自動的に登録します。
1.2.1. TaskletAdapter
ItemReaderとItemWriterのアダプタ同様、TaskletにもTaskletAdapterというSpring Batchが用意するアダプタクラスがあります。これが有用な一例としてはレコードセットのフラグ更新に既存のDAOを使う場合です。TaskletAdapterにより、以下例のように、Taskletのアダプターを記述することなくDAOのメソッドを呼び出せます。
Java Configuration
@Bean public MethodInvokingTaskletAdapter myTasklet() { MethodInvokingTaskletAdapter adapter = new MethodInvokingTaskletAdapter(); adapter.setTargetObject(fooDao()); adapter.setTargetMethod("updateFoo"); return adapter; }
1.2.2. Example Tasklet Implementation
たいていのバッチjobaは、各種リソースのセットアップためメイン処理開始前に実行すべきstepや、そうしたリソースをクリーンアップする処理の終了後に実行すべきstepがあります。巨大なファイルを扱うjobの場合、別の場所へ正常にアップロード完了後にローカルの対象ファイルを削除する事がほとんどです。以下の例(Spring Batch samples projectの抜粋)はまさにそのような事をするTasklet実装の例です。
public class FileDeletingTasklet implements Tasklet, InitializingBean { private Resource directory; public RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception { File dir = directory.getFile(); Assert.state(dir.isDirectory()); File[] files = dir.listFiles(); for (int i = 0; i < files.length; i++) { boolean deleted = files[i].delete(); if (!deleted) { throw new UnexpectedJobExecutionException("Could not delete file " + files[i].getPath()); } } return RepeatStatus.FINISHED; } public void setDirectoryResource(Resource directory) { this.directory = directory; } public void afterPropertiesSet() throws Exception { Assert.notNull(directory, "directory must be set"); } }
上のTasklet実装は所定ディレクトリ内の全ファイルを削除します。executeメソッドは一度だけ呼ばれることに注意してください。あとはStepからこのTaskletを参照します。
Java Configuration
@Bean public Job taskletJob() { return this.jobBuilderFactory.get("taskletJob") .start(deleteFilesInDir()) .build(); } @Bean public Step deleteFilesInDir() { return this.stepBuilderFactory.get("deleteFilesInDir") .tasklet(fileDeletingTasklet()) .build(); } @Bean public FileDeletingTasklet fileDeletingTasklet() { FileDeletingTasklet tasklet = new FileDeletingTasklet(); tasklet.setDirectoryResource(new FileSystemResource("target/test-outputs/test-dir")); return tasklet; }
1.3. Controlling Step Flow
jobで複数stepをグループ化する機能では、あるstepから別のstepへのjob "flows" を制御する方法が必要となります。Stepの失敗が必ずしもJobの失敗を意味しません。また、Stepが次を実行すべきか決定するための'success'が複数種類存在する場合もあります。Stepsのグループ設定次第では、ある特定のstepが全く実行されない場合がありえます。
1.3.1. Sequential Flow
もっともシンプルなflowのケースは、以下イメージのように、すべてのstepをシーケンシャルに実行するjobです。
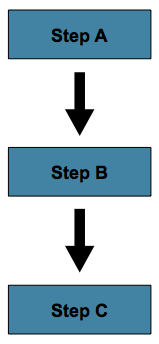
Figure 3. Sequential Flow
こういう設定をするにはstep要素の'next'属性を以下の例のように使います。
Java Configuration
@Bean public Job job() { return this.jobBuilderFactory.get("job") .start(stepA()) .next(stepB()) .next(stepC()) .build(); }
上のケースでは、'step A'がStepリストの最初にあるので最初に実行します。'step A'が正常終了すると、'step B'を実行し、その後は同様です。ただし、'step A'が失敗する場合、Job全体が失敗して、'step B'は実行しません。
1.3.2. Conditional Flow
上記例では、2パターンのみ存在します。
Stepが成功して次のStepを実行する。Stepが失敗するとJobが失敗する。
これで十分なケースも多いです。しかし、失敗にするのではなく、Stepの失敗が別のStepをトリガーするケースはどうでしょうか。以下がそうしたflowのイメージです。
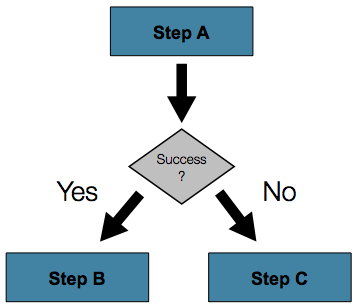
Figure 4. Conditional Flow
複雑なケースを扱うために、Spring Batch namespaceではstep要素内に定義する遷移要素を用意しています。そうした遷移要素の一つがnext要素です。next属性同様、next要素は次に実行するStepをJobに指示します。ただし、属性とは異なり、Stepには任意数のnext要素を指定可能で、その場合失敗時のデフォルトの振る舞いは存在しません。つまり、遷移要素を使う場合、Step遷移に対するすべての振る舞いを明示的に定義する必要があります。なお、単一stepはnext属性とtransition要素両方を指定できません。
next要素にはマッチするパターンと次に実行するstepを、以下サンプルのように、指定します。
Java Configuration
@Bean public Job job() { return this.jobBuilderFactory.get("job") .start(stepA()) .on("*").to(stepB()) .from(stepA()).on("FAILED").to(stepC()) .end() .build(); }
java設定を使う場合はonメソッドにシンプルなパターンマッチングを使い、Step実行の結果であるExitStatusにマッチさせるものを指定します。
パターンには2つの特殊文字を使用可能です。
- "*"は0以上の文字列にマッチ。
- "?"は1文字にマッチ。
例えば、"c*t"は"cat"と"count"にマッチし、"c?t"は"cat"にはマッチするが"count"にはしない。
Stepに配置する遷移要素に上限はありませんが、Step実行が返すExitStatusに対応する要素が無い場合、フレームワークは例外をスローしてJobは失敗します。フレームワークは遷移順序を最もマッチするものからしないもの順で決定します。つまり、上記例で順序を"stepA"に入れ替えたとしても、"FAILED"のExitStatusは"stepC"に遷移します(This means that, even if the ordering were swapped for "stepA" in the example above, an ExitStatus of "FAILED" would still go to "stepC".)。
Batch Status Versus Exit Status
条件付きflowでJobを設定する場合、BatchStatusとExitStatusの違いを意識する事は重要です。BatchStatusはenumで、JobExecutionとStepExecution双方のプロパティであり、フレームワークがJobやStepのステータスを記録するために使います。以下の値のいずれか1つになります。COMPLETED, STARTING, STARTED, STOPPING, STOPPED, FAILED, ABANDONED, UNKNOWN。これらの多くは自己説明的です。COMPLETEDはstepやjobが正常終了した場合のステータスで、FAILEDは失敗時、などです。
以下の例はJava設定で'on'要素を持つものです。
... .from(stepA()).on("FAILED").to(stepB()) ...
一目見た感じでは、'on'がStepのBatchStatusを参照するように見えます。しかし、実際にはStepのExitStatusを参照します。名前が示すように、ExitStatusはそのStepの終了後のステータスを表します。
英語で書くなら、"exit codeがFAILEDであればstepBに遷移する"( "go to stepB if the exit code is FAILED")、です。デフォルトではexit codeはStepのBatchStatusと常に同じになり、これが上記サンプルがなぜ動作するのかの理由です。ただし、exit codeを別の値にしたい場合は? 好例がsamples projectのskip sample jobにあります。
Java Configuration
@Bean public Job job() { return this.jobBuilderFactory.get("job") .start(step1()).on("FAILED").end() .from(step1()).on("COMPLETED WITH SKIPS").to(errorPrint1()) .from(step1()).on("*").to(step2()) .end() .build(); }
step1には3パターンがありえます。
Stepが失敗、jobも失敗。Stepが正常終了。Stepが正常終了するがexit codeはCOMPLETED WITH SKIPS'。この場合、エラー処理に別のstepを実行する。
上記の設定は動作します。ただし、以下例のように、レコードスキップ条件でexit codeを変更するように修正します。
public class SkipCheckingListener extends StepExecutionListenerSupport { public ExitStatus afterStep(StepExecution stepExecution) { String exitCode = stepExecution.getExitStatus().getExitCode(); if (!exitCode.equals(ExitStatus.FAILED.getExitCode()) && stepExecution.getSkipCount() > 0) { return new ExitStatus("COMPLETED WITH SKIPS"); } else { return null; } } }
上のStepExecutionListenerはまず、Stepが正常終了かつStepExecutionのskip countが0より大きい、かどうかをチェックします。両条件を満たす場合、新規ExitStatusをexit code COMPLETED WITH SKIPSで返します。
1.3.3. Configuring for Stop
BatchStatus and ExitStatusの解説を読んだ後、JobでBatchStatusとExitStatusの決定ルールを知りたいと感じたかもしれません。Stepのステータスは実行するコードで決定し、Jobは設定で決定します。
これまでに解説したjob設定はすべて少なくとも一つの遷移無しの最終Stepを持っています。たとえば、以下例のように、step実行後、Jobは終了します。
@Bean public Job job() { return this.jobBuilderFactory.get("job") .start(step1()) .build(); }
Stepに遷移先が無い場合、Jobのステータスは以下のように決定します。
- その最終
StepがExitStatusFAILEDで終了する場合、JobのBatchStatusとExitStatusは両方ともFAILEDになる。 - それ以外の場合、
JobのBatchStatusとExitStatusは両方ともCOMPLETEDになる。
ある種のバッチジョブ、シンプルなシーケンシャルstepのjobなどでは、上記の終了ルールで十分ですが、カスタム定義のjob停止が必要な場合もあります。そうした用途のために、Spring BatchはJobを停止するための遷移要素を3つ用意しています(前述のnext要素に加えて)。それらの停止要素はJobを特定のBatchStatusで停止します。なお、その停止遷移要素はJobのいずれのStepsのBatchStatusあるいはExitStatusのどちらにも影響を与えません。これらの要素はJobの最終ステータスにだけ影響を与えます。たとえば、jobのすべてのstepがFAILEDでありながら、jobはCOMPLETEDに出来ます。
Ending at a Step
stepを終了するとBatchStatusがCOMPLETEDでjobを停止します。ステータスCOMPLETEDで終了するJobはリスタート出来ません(フレームワークがJobInstanceAlreadyCompleteExceptionをスローする)。
Java設定を使う場合、そのタスクには'end'メソッドを使います。また、endメソッドはJobのExitStatusをカスタマイズするための'exitStatus'パラメータを取ることも可能です。'exitStatus'を指定しないはデフォルトでExitStatusがCOMPLETEDとなり、BatchStatusもそうなります。
以下のケースでは、step2が失敗するとJobはBatchStatus COMPLETEDおよびExitStatus COMPLETEDで停止してstep3は実行しません。そうでない場合、step3に遷移します。なお、step2が失敗する場合はJobはリスタート出来ません(ステータスがCOMPLETEDなので)。
@Bean public Job job() { return this.jobBuilderFactory.get("job") .start(step1()) .next(step2()) .on("FAILED").end() .from(step2()).on("*").to(step3()) .end() .build(); }
Failing a Step
所定ポイントでstepを失敗するよう設定するとJobはBatchStatus FAILEDで停止します。endと異なり、Job失敗でリスタート不能にはなりません。
以下のケースでは、step2が失敗するとJobはBatchStatus FAILED ExitStatus EARLY TERMINATIONで停止してstep3は実行しません。そうでない場合、step3に遷移します。また、step2が失敗してJobをリスタートすると、step2から再開します。
Java Configuration
@Bean public Job job() { return this.jobBuilderFactory.get("job") .start(step1()) .next(step2()).on("FAILED").fail() .from(step2()).on("*").to(step3()) .end() .build(); }
Stopping a Job at a Given Step
特定のstepでjobを停止する設定をすると、JobはBatchStatus STOPPEDで停止します。Job停止により処理は一時停止するため、オペレーターはJobの再開前になんらかの作業が出来ます。
java設定の場合、stopAndRestartメソッドは'restart'属性を必要とし、この属性にはJobリスタート時にピックアップするstepを指定します。
以下のケースでは、step1がCOMPLETEで終了するとjobは停止します。リスタートするとstep2から再開します。
@Bean public Job job() { return this.jobBuilderFactory.get("job") .start(step1()).on("COMPLETED").stopAndRestart(step2()) .end() .build(); }
1.3.4. Programmatic Flow Decisions
あるケースでは、ExitStatus以外の情報も使用して次に実行するstepを決定したい場合があります。この場合、以下サンプルのように、決定を行うJobExecutionDeciderを使用します。
public class MyDecider implements JobExecutionDecider { public FlowExecutionStatus decide(JobExecution jobExecution, StepExecution stepExecution) { String status; if (someCondition()) { status = "FAILED"; } else { status = "COMPLETED"; } return new FlowExecutionStatus(status); } }
次の例では、Java設定でJobExecutionDeciderを実装するbeanをnextに直接渡しています。
Java Configuration
@Bean public Job job() { return this.jobBuilderFactory.get("job") .start(step1()) .next(decider()).on("FAILED").to(step2()) .from(decider()).on("COMPLETED").to(step3()) .end() .build(); }
1.3.5. Split Flows
これまでに解説したケースのJobはいずれも線形に一度に1つのstepを実行します。この一般的なスタイルに加えて、Spring Batchはjobをparallel flowsに設定可能です。
Java設定ではビルダーを用いて設定をスプリットできます。以下に示す例は、'split'要素は複数の'split'要素を持ち、そこで個々のflowを定義します。また、'split'要素には、これまでに解説した遷移要素、'next'属性や'next'要素・'end'や'fail'要素、を入れられます。
@Bean public Job job() { Flow flow1 = new FlowBuilder<SimpleFlow>("flow1") .start(step1()) .next(step2()) .build(); Flow flow2 = new FlowBuilder<SimpleFlow>("flow2") .start(step3()) .build(); return this.jobBuilderFactory.get("job") .start(flow1) .split(new SimpleAsyncTaskExecutor()) .add(flow2) .next(step4()) .end() .build(); }
1.3.6. Externalizing Flow Definitions and Dependencies Between Jobs
jobのflowの一部を別のbeanとして切り出すことで、再使用できます。これには2通りの方法があります。1つは単に、以下に示すように、flowをどこか別の場所で定義したbeanとして宣言します。
Java Configuration
@Bean public Job job() { return this.jobBuilderFactory.get("job") .start(flow1()) .next(step3()) .end() .build(); } @Bean public Flow flow1() { return new FlowBuilder<SimpleFlow>("flow1") .start(step1()) .next(step2()) .build(); }
上の例のように外部flowを定義すると、インラインで定義しているかのように外部flowをjobにstepを追加できることにになります。この方法により、多数のjobが同じテンプレートflowを参照可能となり、そのテンプレートを別のflowに組み込むことも出来ます。また、個々のflowのインテグレーションテストを分離するのにも役立ちます。
flow外部化の別の方法はJobStepの使用です。JobStepはFlowStepと似てますが、flow内のstepを別のjob実行として実際に作成・実行します。
以下はJobStepの例です。
Java Configuration
@Bean public Job jobStepJob() { return this.jobBuilderFactory.get("jobStepJob") .start(jobStepJobStep1(null)) .build(); } @Bean public Step jobStepJobStep1(JobLauncher jobLauncher) { return this.stepBuilderFactory.get("jobStepJobStep1") .job(job()) .launcher(jobLauncher) .parametersExtractor(jobParametersExtractor()) .build(); } @Bean public Job job() { return this.jobBuilderFactory.get("job") .start(step1()) .build(); } @Bean public DefaultJobParametersExtractor jobParametersExtractor() { DefaultJobParametersExtractor extractor = new DefaultJobParametersExtractor(); extractor.setKeys(new String[]{"input.file"}); return extractor; }
job parameters extractorはStepのExecutionContextを実行JobのJobParametersに変換する方法を決定するものです。JobStepはjobとstepのモニタリングとレポーティングに細かいオプションをつけたい場合に有用です。また、JobStepは以下の質問に対する回答でもあります。"job間の依存関係をどのように作るのか?" これは大規模システムを小さいモジュールとjobのflow制御に分割する優れた方法です。
1.4. Late Binding of Job and Step Attributes
これまでに解説したXMLとフラットファイルサンプルはいずれもファイル取得にSpringのResourceを使用します。ResourceのgetFileがjava.io.Fileを返すので機能します。XMLとフラットファイルのリソースは以下サンプルのようにSpringの機能で設定できます。
Java Configuration
@Bean public FlatFileItemReader flatFileItemReader() { FlatFileItemReader<Foo> reader = new FlatFileItemReaderBuilder<Foo>() .name("flatFileItemReader") .resource(new FileSystemResource("file://outputs/file.txt")) ... }
上のResourceは指定のファイルシステムロケーションからファイルをロードします。注意点として、抽象ロケーション(absolute locations)はスラッシュ2個(//)で開始します。たいていのSpringアプリケーションで、このやり方で十分であり、これらリソース名はコンパイル時に決定しているためです。ただし、バッチのケースでは、ファイル名はjobのパラメータで動的に決定する場合もあります。この場合にはシステムプロパティを読み込み'-D'パラメータを使います。
以下はプロパティからファイル名を読み込み方法です。
Java Configuration
@Bean public FlatFileItemReader flatFileItemReader(@Value("${input.file.name}") String name) { return new FlatFileItemReaderBuilder<Foo>() .name("flatFileItemReader") .resource(new FileSystemResource(name)) ... }
この方法を動かすにはシステム引数(-Dinput.file.name="file://outputs/file.txt"など)を指定します。
※ ここでは``PropertyPlaceholderConfigurerが使用可能ですが、システムプロパティが常にセットされる場合は不要です。これはSpringのResourceEditor```がシステムプロパティのフィルタリングとプレースホルダー置換を行うためです。
また、バッチ設定において、システムプロパティではなくjobのJobParametersでファイル名をパラメータ化してアクセスしたい場合があります。これをするには以下のように、Spring Batchでは各種JobとStepで遅延バインディングが可能です。
Java Configuration
@StepScope @Bean public FlatFileItemReader flatFileItemReader(@Value("#{jobParameters['input.file.name']}") String name) { return new FlatFileItemReaderBuilder<Foo>() .name("flatFileItemReader") .resource(new FileSystemResource(name)) ... }
以下例のようにJobExecutionとStepExecutionのExecutionContextは同様な方法でアクセス可能です。
Java Configuration
@StepScope @Bean public FlatFileItemReader flatFileItemReader(@Value("#{jobExecutionContext['input.file.name']}") String name) { return new FlatFileItemReaderBuilder<Foo>() .name("flatFileItemReader") .resource(new FileSystemResource(name)) ... }
Java Configuration
@StepScope @Bean public FlatFileItemReader flatFileItemReader(@Value("#{stepExecutionContext['input.file.name']}") String name) { return new FlatFileItemReaderBuilder<Foo>() .name("flatFileItemReader") .resource(new FileSystemResource(name)) ... }
※ 遅延バインディングを使うbeanはscope="step"を宣言する必要があります。詳細はStep Scopeを参照。
1.4.1. Step Scope
上で取り上げた遅延バインディングの例は、以下サンプルのように、bean定義にすべて"step"スコープを宣言しています。
Java Configuration
@StepScope @Bean public FlatFileItemReader flatFileItemReader(@Value("#{jobParameters[input.file.name]}") String name) { return new FlatFileItemReaderBuilder<Foo>() .name("flatFileItemReader") .resource(new FileSystemResource(name)) ... }
遅延バインディングを使うにはStepスコープが必要で、これは属性を参照するには、Step開始までbeanをインスタンス化出来ないためです。このスコープはSpringコンテナのデフォルトには含まれないので、scopeの明示的な追加が必要です。追加するには、batch namespace・StepScopeのbean定義を明示的に追加・@EnableBatchProcessingの使用、のどれか1つを使用します。以下はbatch namespaceの使用例です。
<beans xmlns="http://www.springframework.org/schema/beans" xmlns:batch="http://www.springframework.org/schema/batch" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="..."> <batch:job .../> ... </beans>
以下の例は明示的なbean定義の追加です。
<bean class="org.springframework.batch.core.scope.StepScope" />
1.4.2. Job Scope
Jobスコープは、Spirng Batch 3.0で導入され、Stepスコープと同様のものですがJobコンテキストのスコープで、ジョブ実行時にそのbeanのインスタンスが1つだけになります。また、参照の遅延バインディングが可能で、JobContextを#{..}でアクセスできます。この機能により、以下例に示すように、jobやjob execution contextおよびジョブパラメータ、からbeanプロパティを取得できます。
Java Configuration
@JobScope @Bean public FlatFileItemReader flatFileItemReader(@Value("#{jobParameters[input]}") String name) { return new FlatFileItemReaderBuilder<Foo>() .name("flatFileItemReader") .resource(new FileSystemResource(name)) ... }
Java Configuration
@JobScope @Bean public FlatFileItemReader flatFileItemReader(@Value("#{jobExecutionContext['input.name']}") String name) { return new FlatFileItemReaderBuilder<Foo>() .name("flatFileItemReader") .resource(new FileSystemResource(name)) ... }
Springコンテナにはデフォルトで含まれないスコープなので、明示的な追加が必要です。batch namespace・JobScopeのbean定義を明示的に追加・@EnableBatchProcessingの使用、のどれか1つを使用します。以下はbatch namespaceの使用例です。
<beans xmlns="http://www.springframework.org/schema/beans" xmlns:batch="http://www.springframework.org/schema/batch" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="..."> <batch:job .../> ... </beans>
以下の例はJobScopeのbeanを明示的に追加しています。
<bean class="org.springframework.batch.core.scope.JobScope" />